YOLOv2
batch norm
舍弃全连接层和dropout,每次卷积后加入batch normalization。
batch norm的作用
具有统一规格的数据能让神经网络更好地学习到数据的规律;批归一化在非线性激活函数前,使梯度不会出线为0;
高分辨率预训练分类网络
目前的大部分检测模型都会使用主流分类网络(如vgg、resnet)在ImageNet上的预训练模型作为特征提取器,而这些分类网络大部分都是以小于256×256的图片作为输入进行训练的,低分辨率会影响模型检测能力。
YOLO v2将输入图片的分辨率提升448×448,为了使网络适应新的分辨率,YOLO v2先在ImageNet上以224×224进行训练,然后再以448×448的分辨率对网络进行10个epoch的微调,让网络适应高分辨率的输入。通过使用高分辨率的输入,YOLO v2的mAP提升了约4%。
采用Anchor Box
anchor box是通过对真实框聚类得到的,得到5种不同大小的anchor box。
anchor box只有w和h,没有中心点。
尺寸聚类
聚类的目的是为了提高选取的Anchor Box和同一个聚类下的gt框之间的IOU,采用的距离公式如下:
- centroid为聚类时被选作中心的bounding box
box为其他的bounding box
对box进行K-means的步骤为:
- 随机选取K个box作为初始anchor;
- 使用IOU度量,将每个box分配给与其距离最近的anchor;
- 计算每个簇中所有box宽和高的均值,更新anchor;
- 重复2、3步,直到anchor不再变化,或者达到了最大迭代次数。
直接位置预测
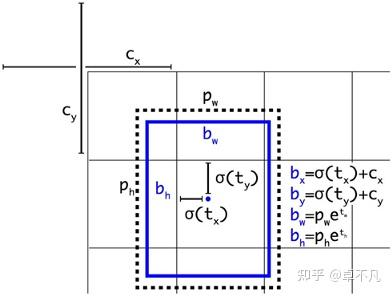
tx,ty,tw,th是预测值,cx和cy是grid cell左上角位置,pw和ph是anchor box的值,通过计算即可得到预测框在特征图上的位置,从而得到在原图的位置;
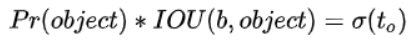
t0是预测值,进行σ变换后作为置信度的值。
注:用IOU最大的去进行回归,Pr(object)的值是1,其余是0;
网络结构
YOLOv2采用了一个新的特征提取主干 Darknet-19,包括19个卷积层,5个maxpooling层;
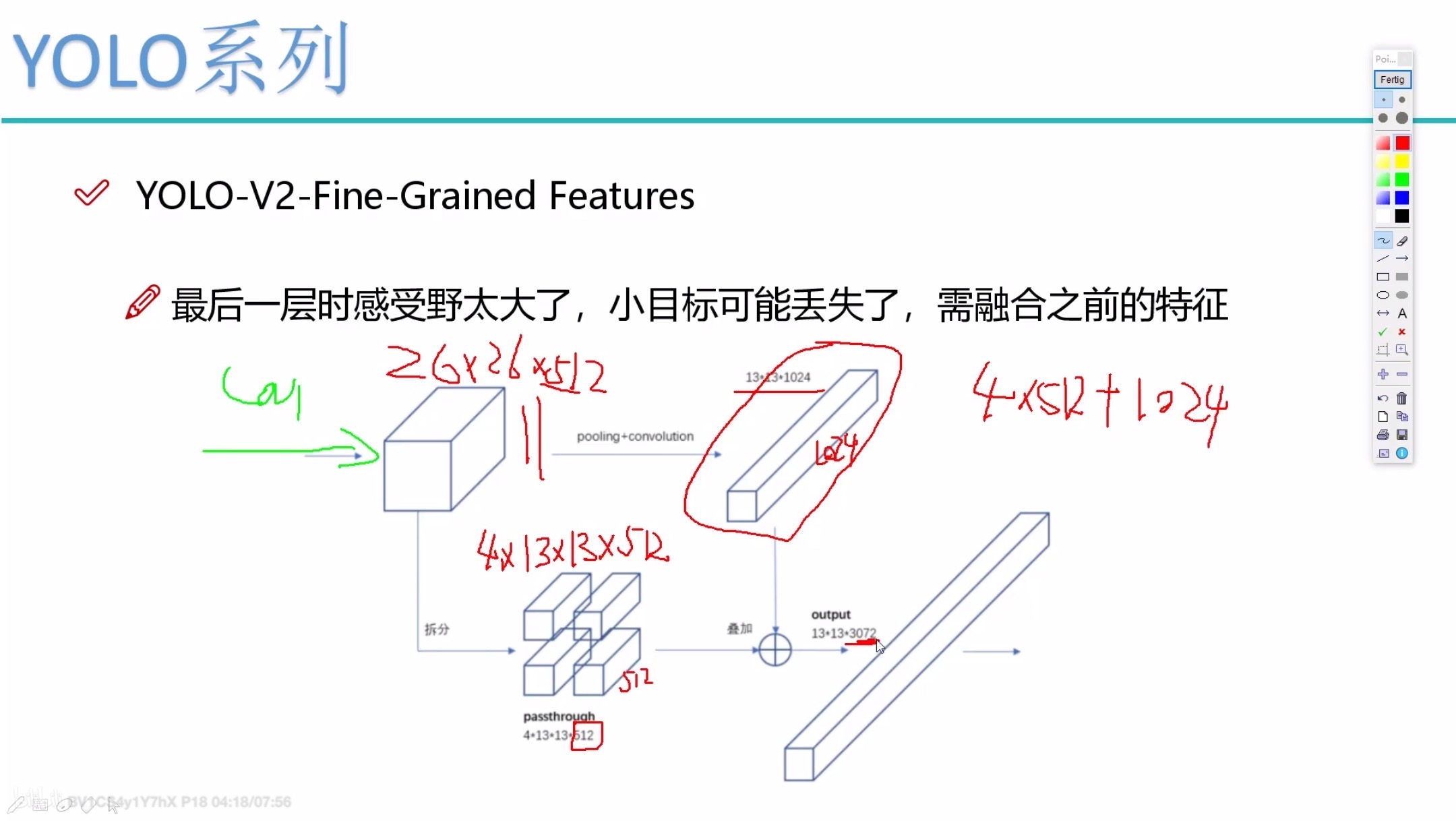
特征融合
YOLO v1和YOLO v2输出对比
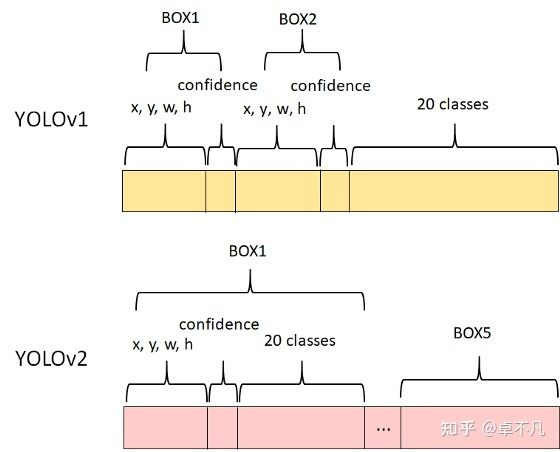
YOLOv2的输出是一个13 13 125的一个张量。
多尺度训练
训练尺度的大小必须为32的倍数,最小320,最大640;
使用多尺度训练时,然后只需要修改对最后检测层的处理就可以重新训练。
anchor box和bounding box的区别
- anchor box是静止的框,随着神经网络的训练是不变的;
- anchor box只有宽高,不需要中心点(也可以理解为中心点为grid cell左上角坐标)
- bounding box是动态的框,它是根据预测值偏移量(tx,ty,tw,th)和anchor box生成的;
- 在这里计算的是bounding box与GroundTruth之间的误差;
- 若设GroundTruth在anchor box的偏移量为(dx,dy,dw,dh),那么误差为(tx,ty,tw,th)与(dx,dy,dw,dh)的误差;
- 详细看YOLO v2和V3 关于设置生成anchorbox,Boundingbox边框回归的个人理解
训练阶段
- 第一阶段:就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 224*224 ,共训练160个epochs;
- 第二阶段:将网络的输入调整为 448*448 ,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%;
- 第三个阶段:修改Darknet-19分类模型为检测模型,移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个 331024卷积层,同时增加了一个passthrough层,最后使用 11 卷积层输出预测结果,输出的channels数为:**num_anchors\(5+num_classes)** ,和训练采用的数据集有关系。由于anchors数为5,对于VOC数据集(20种分类对象)输出的channels数就是125。
损失函数
