YOLOv3的理解和认识
参考
代码:https://github.com/bubbliiiing/yolo3-pytorch
博客:https://blog.csdn.net/weixin_44791964/article/details/105310627
模型
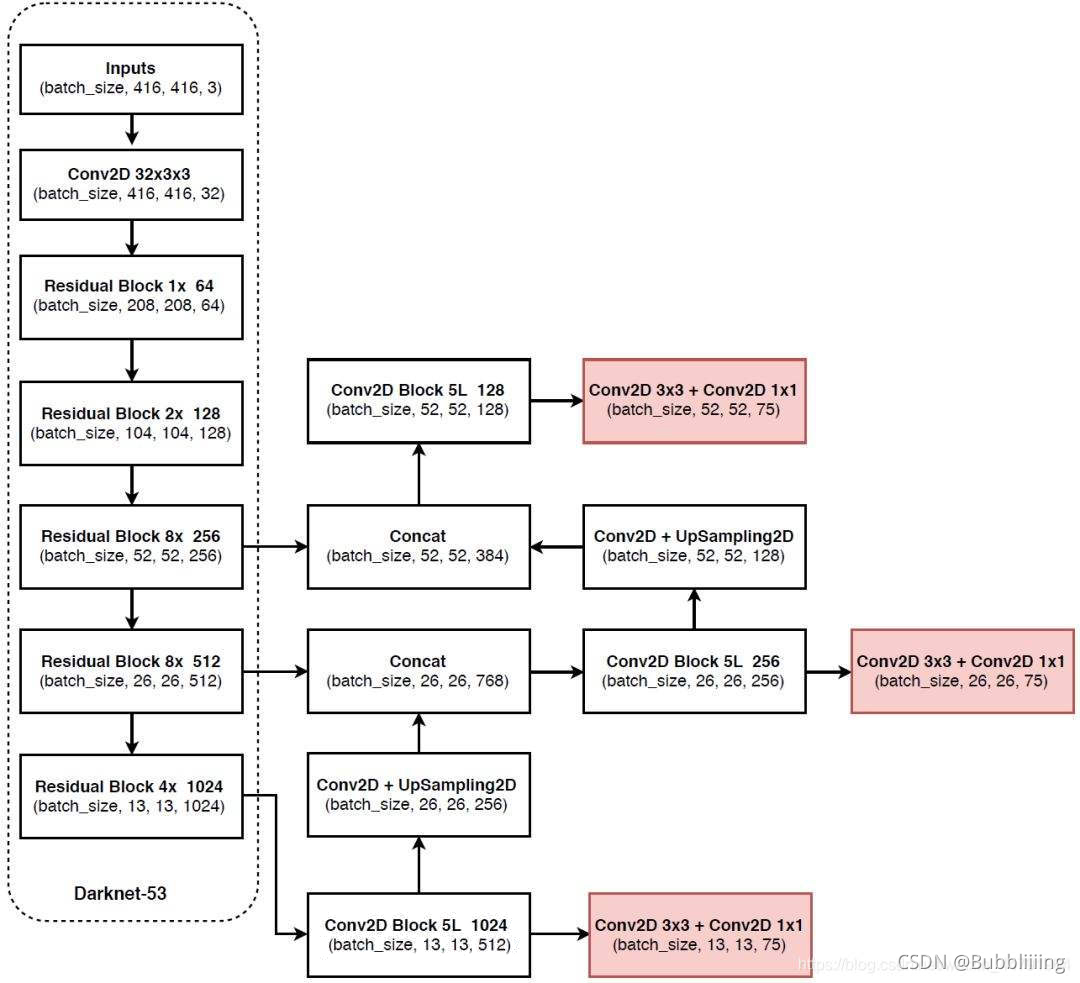
- 主干提取网络采用的是darknet52;
- 在darknet52中,优点是采用了残差连接和1×1和3×3的卷积核连接使用,1×1和3×3的卷积核连接使用可以有效的减少参数量;
- 在检测网络中采用了多尺度特征融合,能够有效提高算法的检测精度;
- 在yolov3中有3种在不同尺寸特征图上的预测结果,以输入图像是416×416大小为例,分别会生成尺寸为52×52、26×26、13×13的特征图,分别预测小、中、大目标;
损失函数
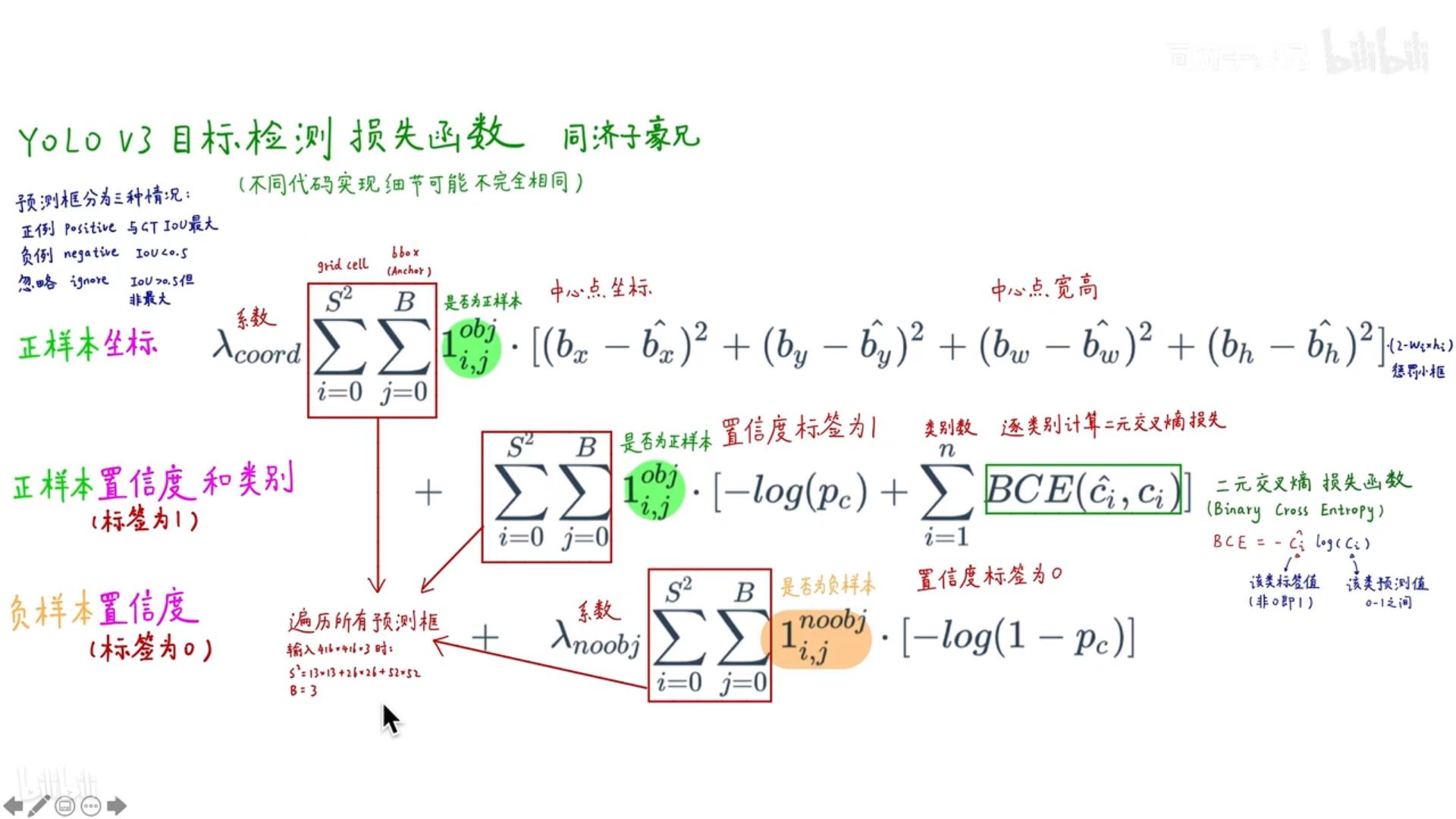
损失函数包括四部分,分别为正样本坐标损失、正样本类别损失、正样本置信度损失和负样本置信度损失。
注:所有样本=正样本+负样本+忽略样本
正样本:真正预测物体的预测框;
忽略样本:不是真正预测物体的预测框,但是与真实框的最大IOU大于0.5
负样本:不是真正预测物体的预测框,但是与真实框的最大IOU小于0.5
正样本坐标损失
- 坐标是用x,y,w,h进行表示,分别为中心点坐标和框的宽高的偏移量;
- 在代码中计算损失是用的BCELoss;
- 在对标签数据进行处理时,对于没有物体的anchor,x,y,w,h,conf和cls都设置为0;
- 对小框的惩罚项:对真正预测物体的anchor进行设置,设置的值为该anchor真实的w和h的乘积;其余没有真实物体的值设置为0;
- 对4中求出的最终求出的结果,要用2减去;
- 在代码中,对小框的惩罚项到乘到标签数据的x,y,w和h上面;
- 如何惩罚小框:惩罚小框就是使损失值变大,对于存在物体的anchor的框较小时,对应的w和h也更小(因为w和h代表宽高的偏移量),因此乘积也就更小,当用2减去该值是,所得到的的值就越大,乘到损失函数上就会使损失变大;
正样本类别损失
- 正样本类别损失的计算方式采用的BCELoss;
- 计算时每个真实目标物体的类别采用的是one_hot编码的数据,预测的类别是采用的预测数据,如[0,0,1]和[0.3,0.5,0.2];
正样本置信度损失和负样本置信度损失
- 正样本置信度损失和负样本置信度损失都直接采用BCELoss进行计算;
- 该处的置信度是该bbox是否有物体的置信度;
训练阶段
- 通过dataloader获取在图片大小是1×1的条件下的x,y,w,h;
- 然后转化为在当前特征图上的相对应的偏移量traget;
- 把9种不同大小的anchor和真实框进行IOU(该处的IOU是两个矩形的中心点重合),获取每个真实框与anchor最大IOU的索引;
- 通过target获取真实框所在特征图的grid cell的位置;
- 分别对y_true和noobj_mask进行设置(noobj_mask表示没有物体的索引);
- 通过预测值计算在当前特征图上的x,y,w,h,得出预测值;
- 在当前特征图下计算真实框和anchor的IOU(普通IOU;若真实框为3,anchor为100,则结果的shape为[3,100]);
- 通过7获取每个先验框与真实框的最大重合度;若最大重合度的IOU大于0.5,则忽略该预测框;
- 将以上得到的值交给损失函数去计算;
预测阶段
- 预测出偏移量;
- 得到中心点的坐标和宽高(在当前特征图上);
- 将2中得到的坐标进行归一化(即相当于放在1×1的特征图上);
- 通过处理得到预测框左上角和右下角的坐标;
- 通过置信度进行抑制(具体细节:让每个anchor的置信度和它预测出各个类别的概率相乘的结果去和置信度分数去比较,大于置信度分数则保留,否则则剔除);
- 然后按照类别进行非极大值抑制nms(nms只要抑制IOU,但是要传conf),获取最终的结果;
通过对坐标进行计算,得到在原图(真正图片)上的中心点和宽高;
目标检测常见名词区分
bbox:指预测框(在anchor的基础上调整过后的预测框);
grid cell:指图像划分成的小格格;
ground truth:指人工标注框;
anchor:指初始化的预测框;