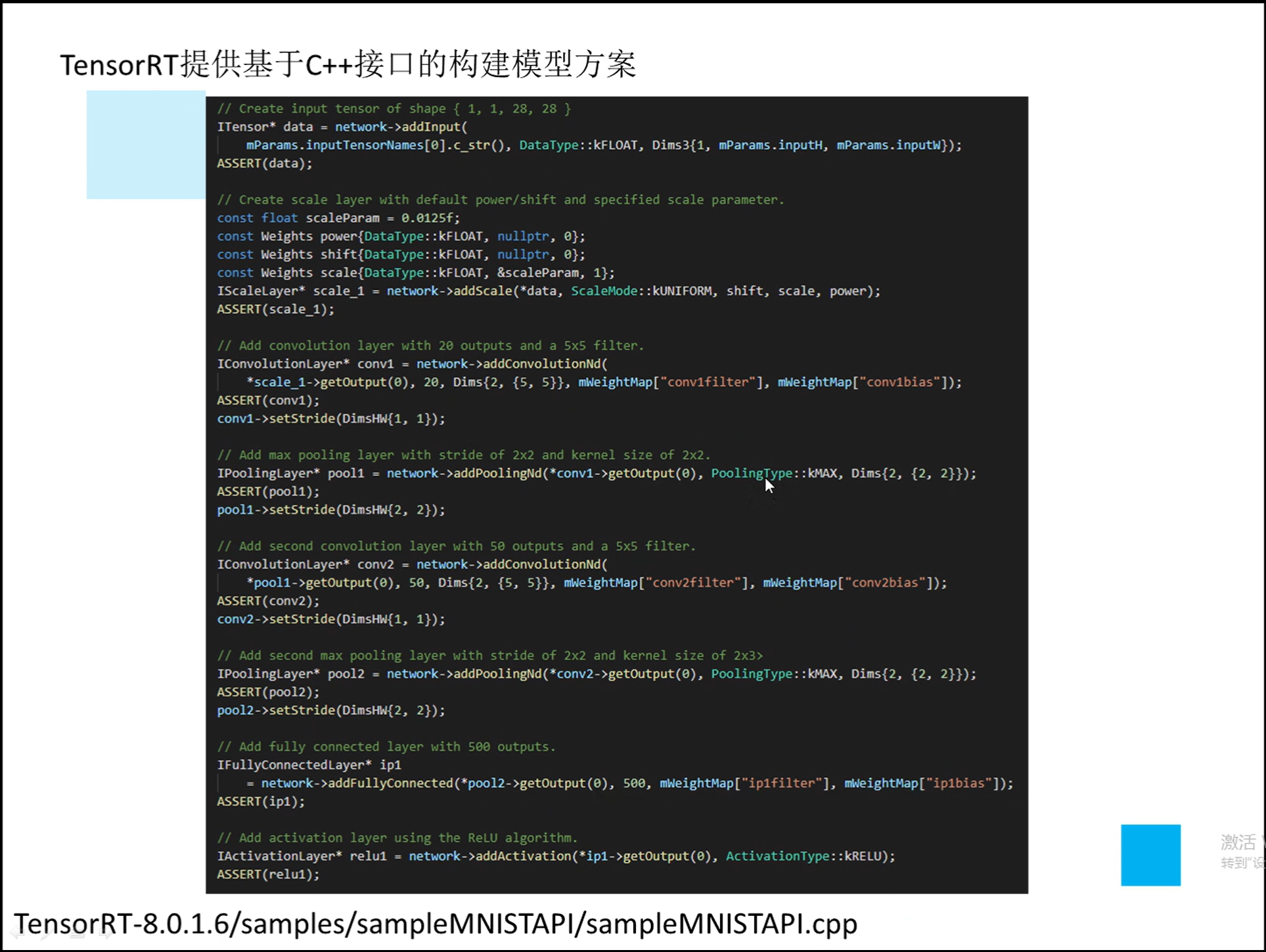
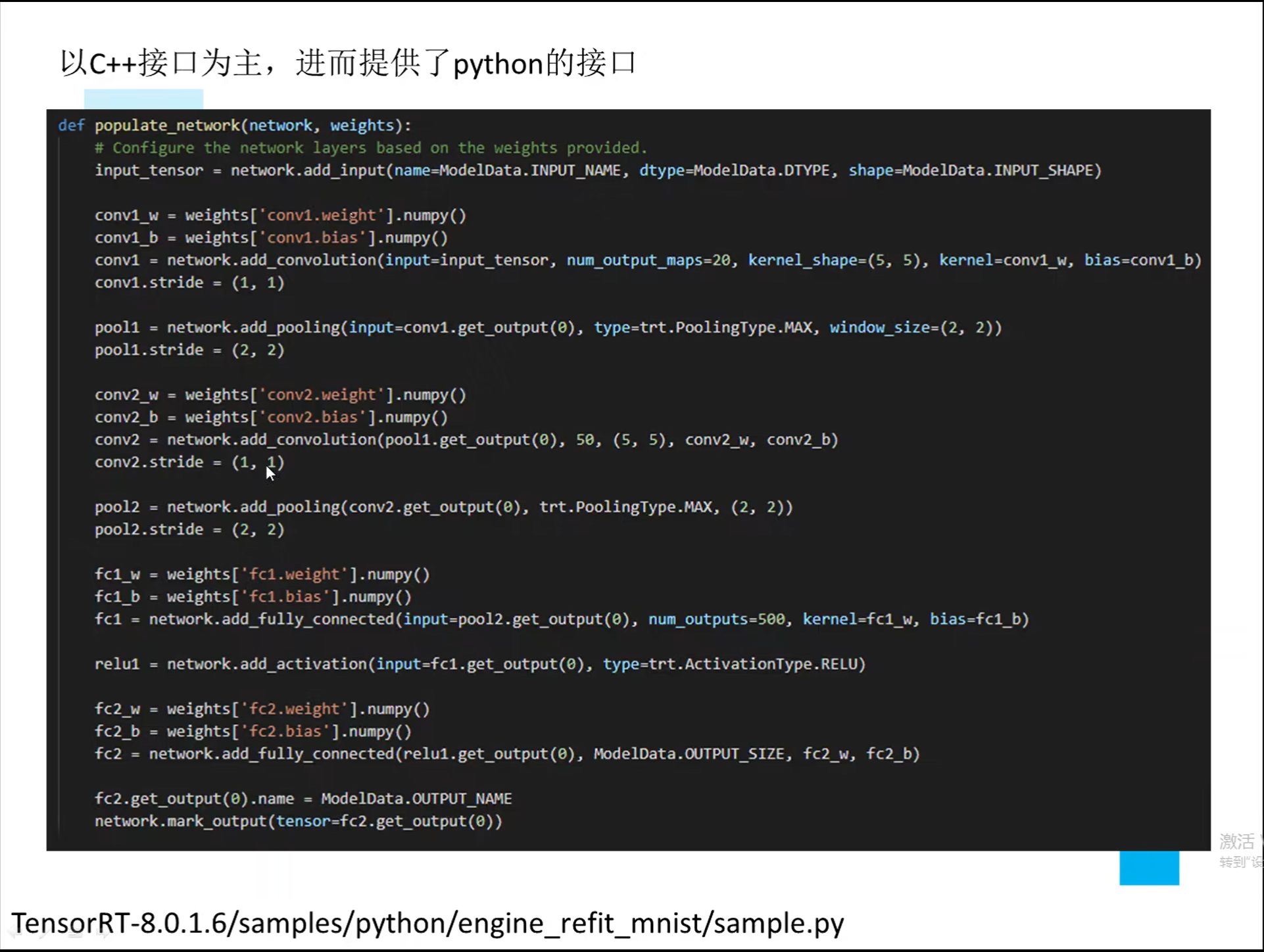
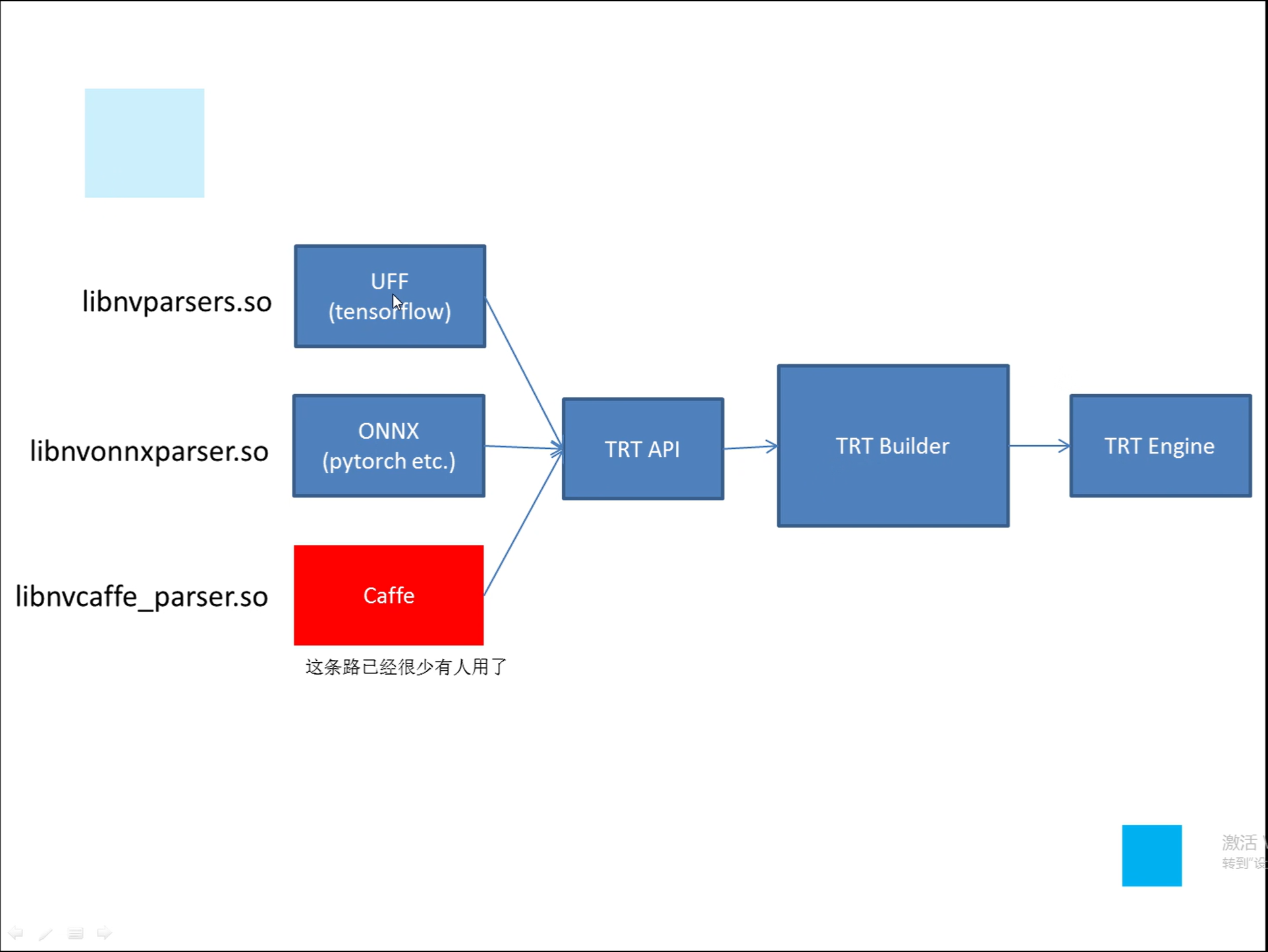
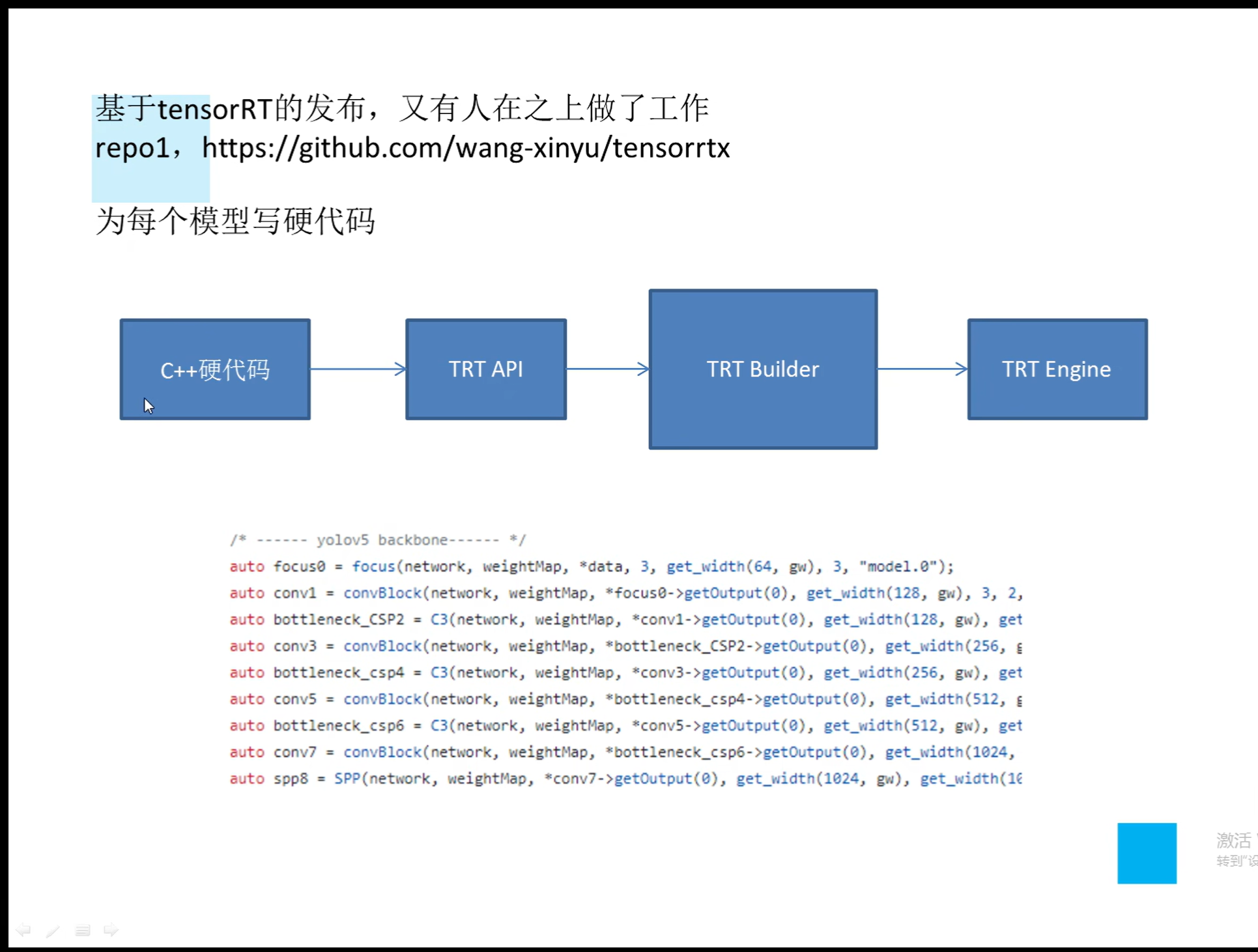
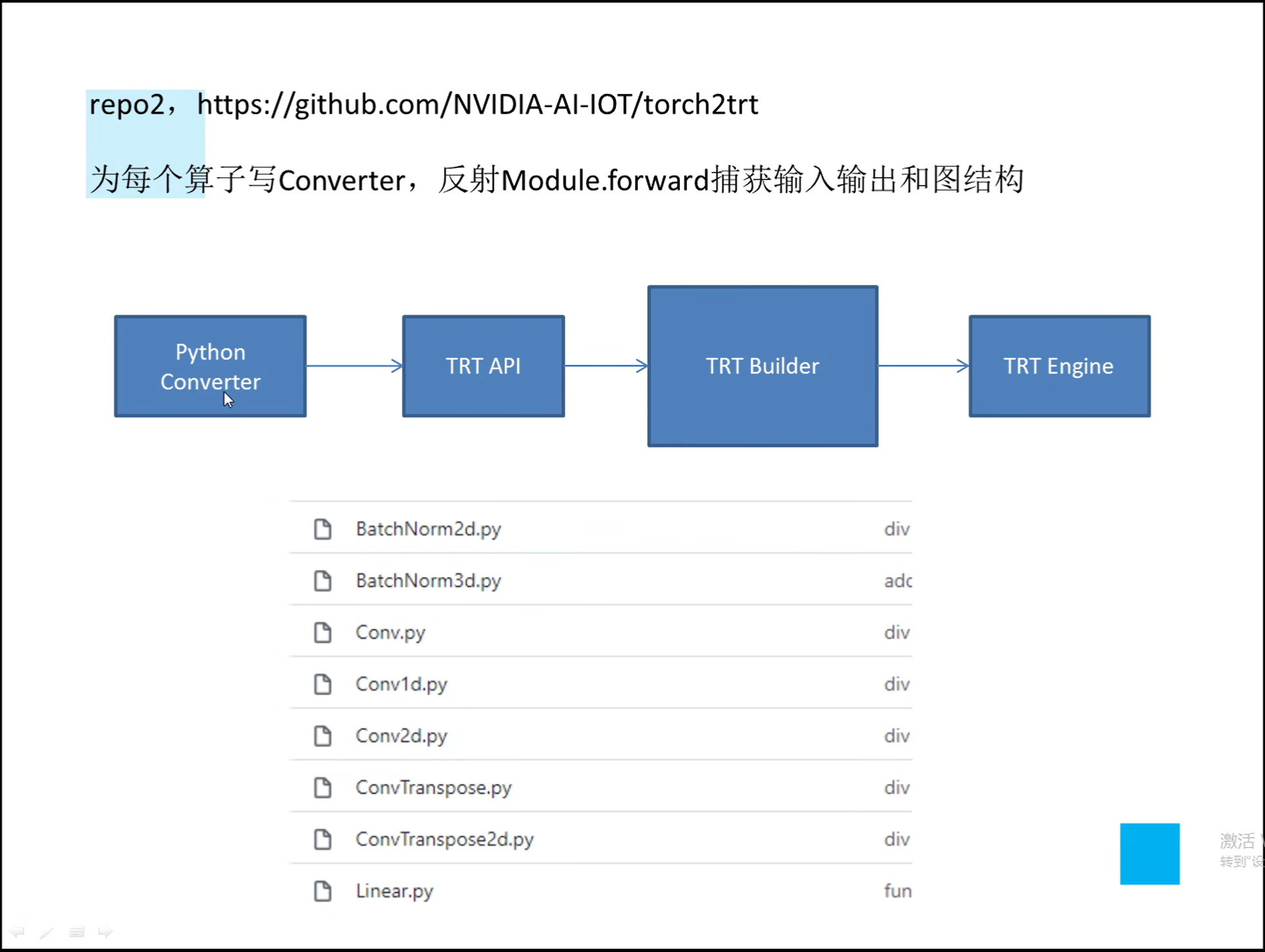
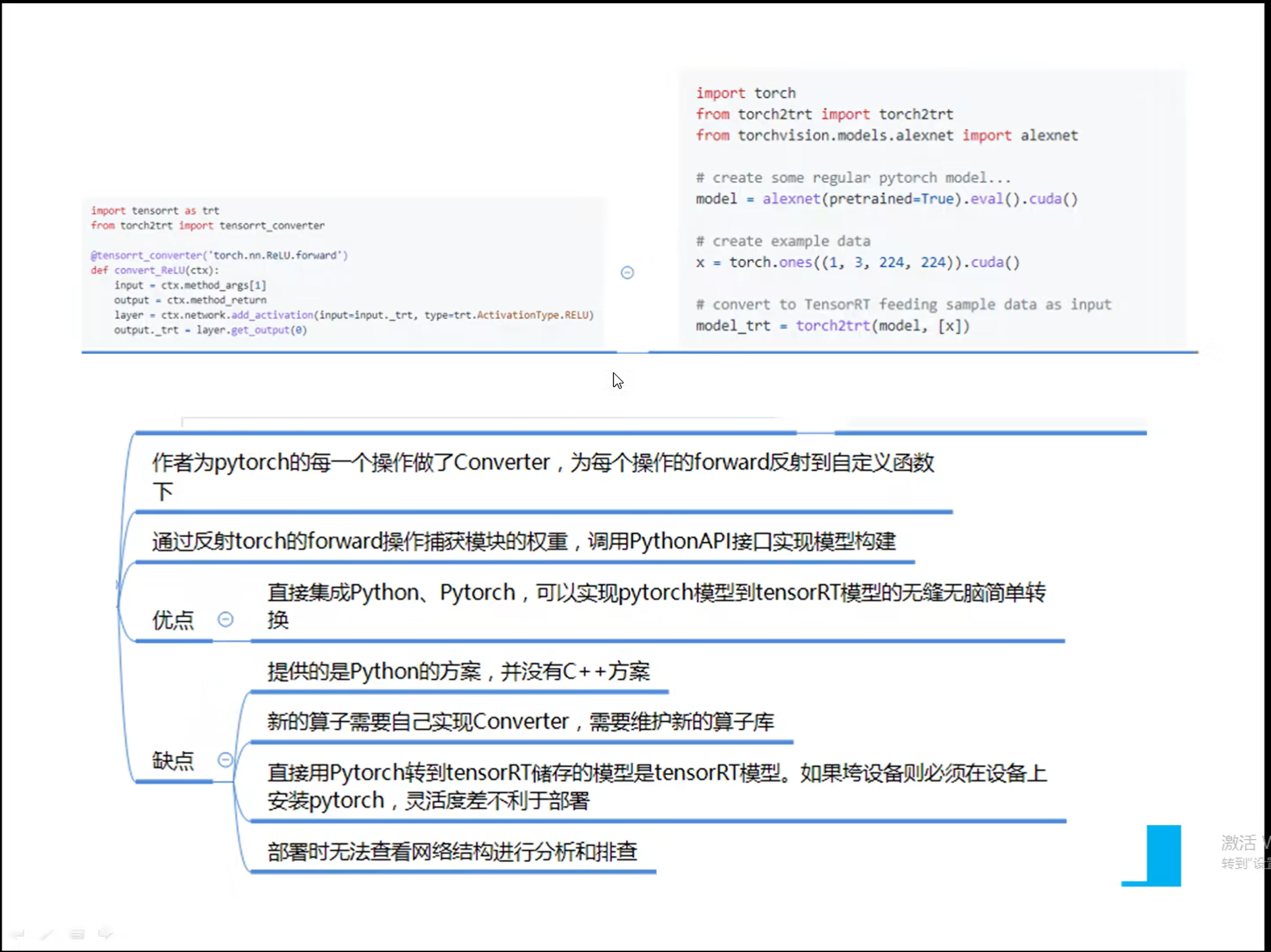
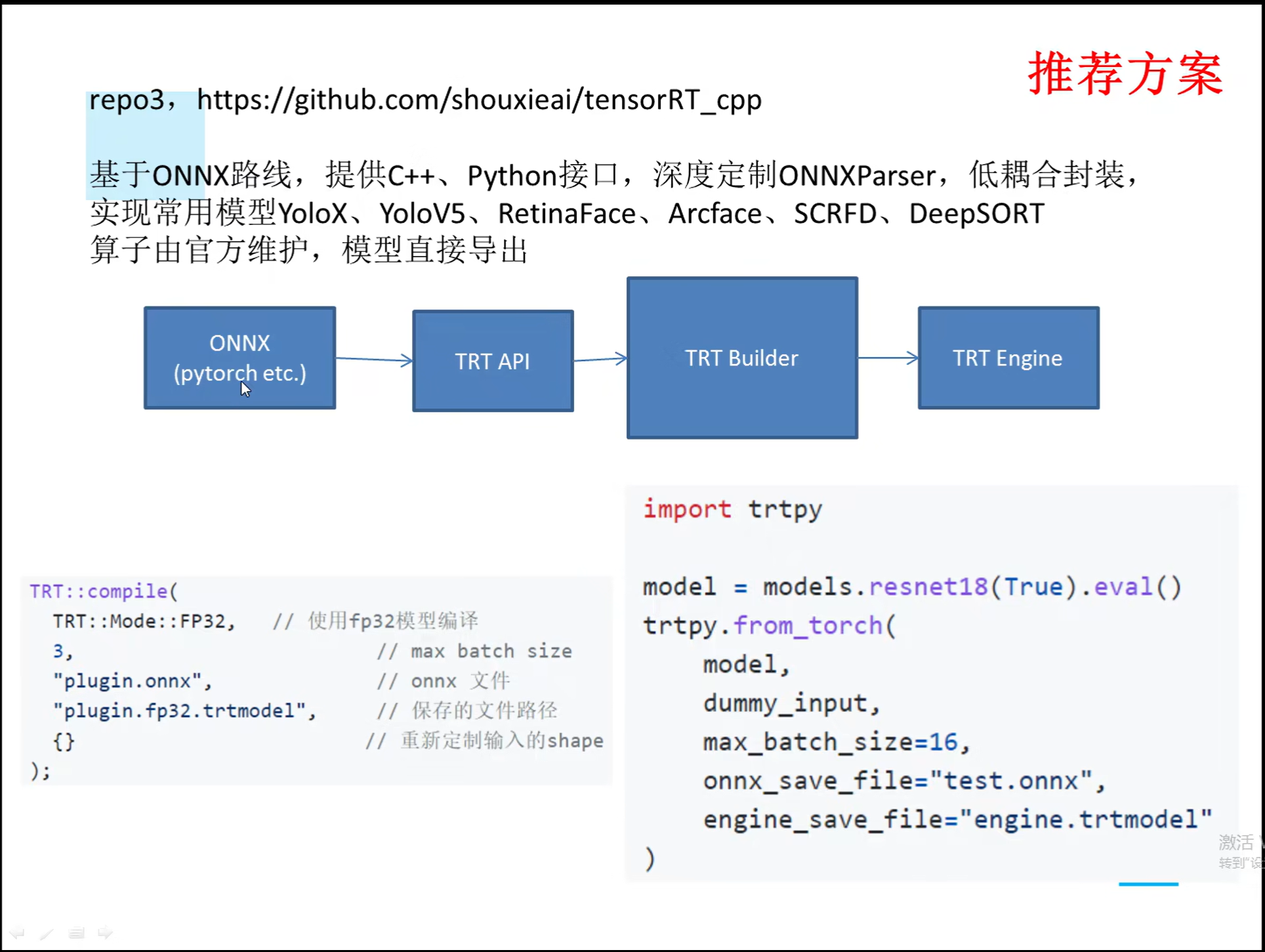
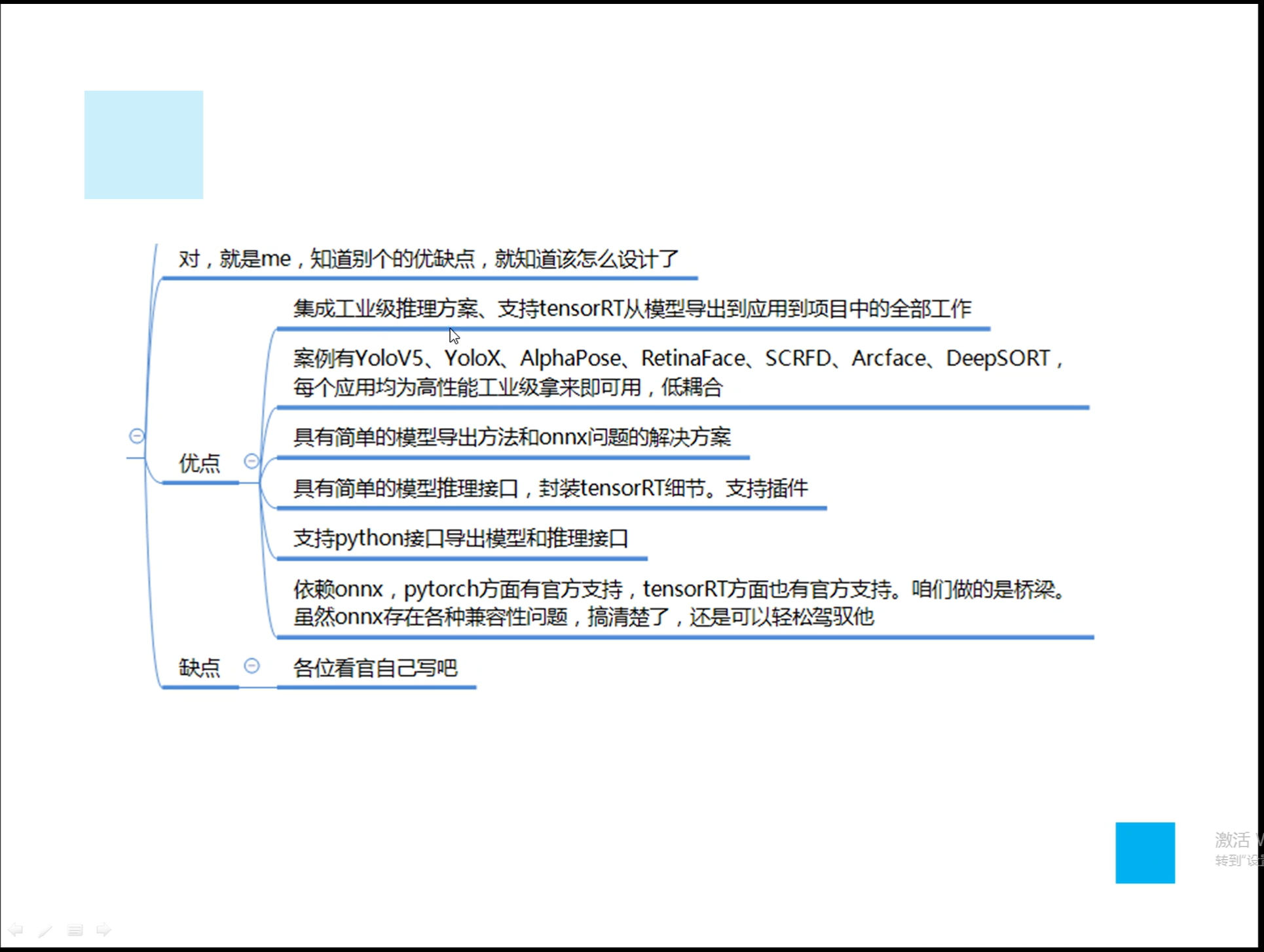
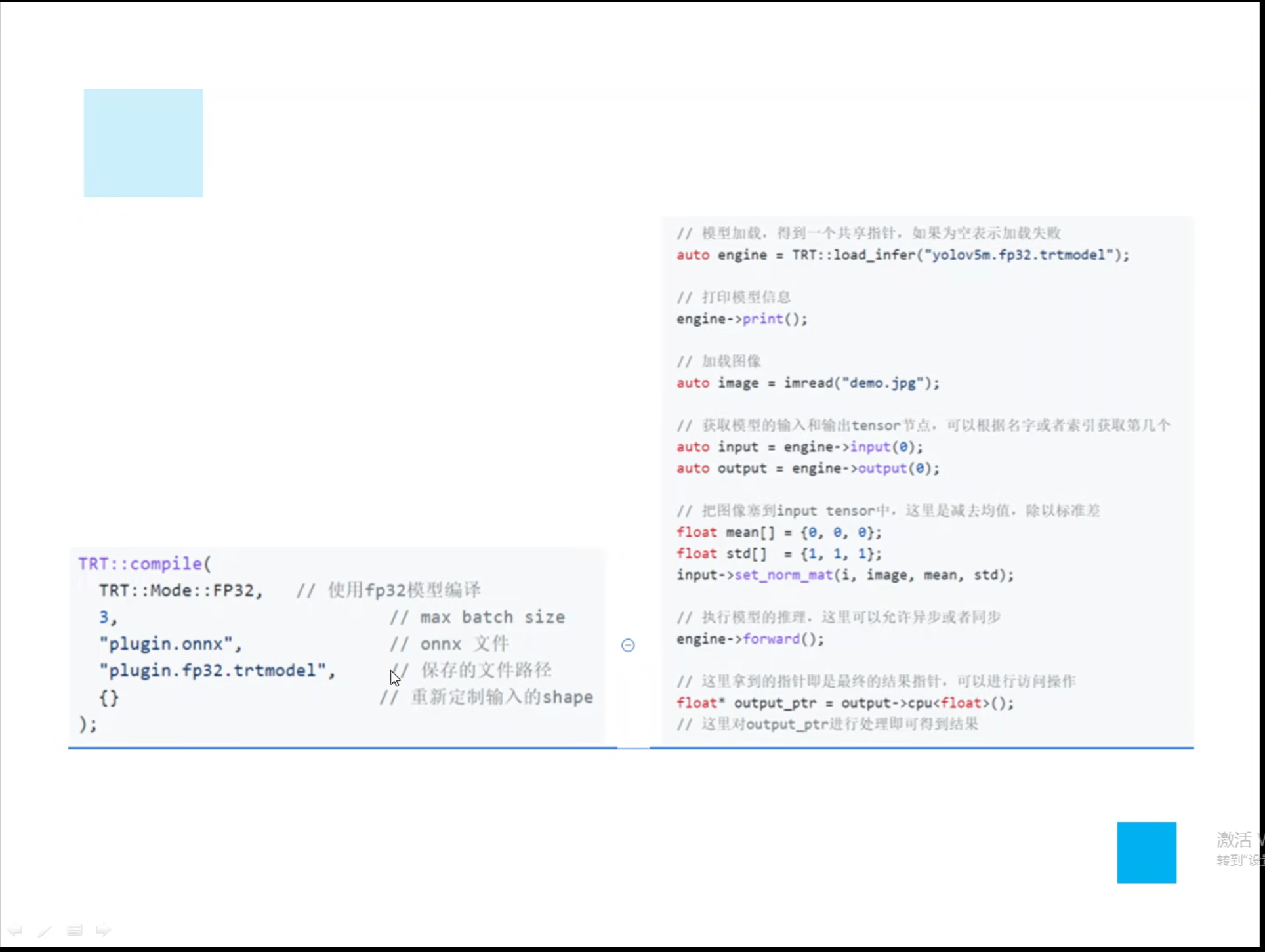
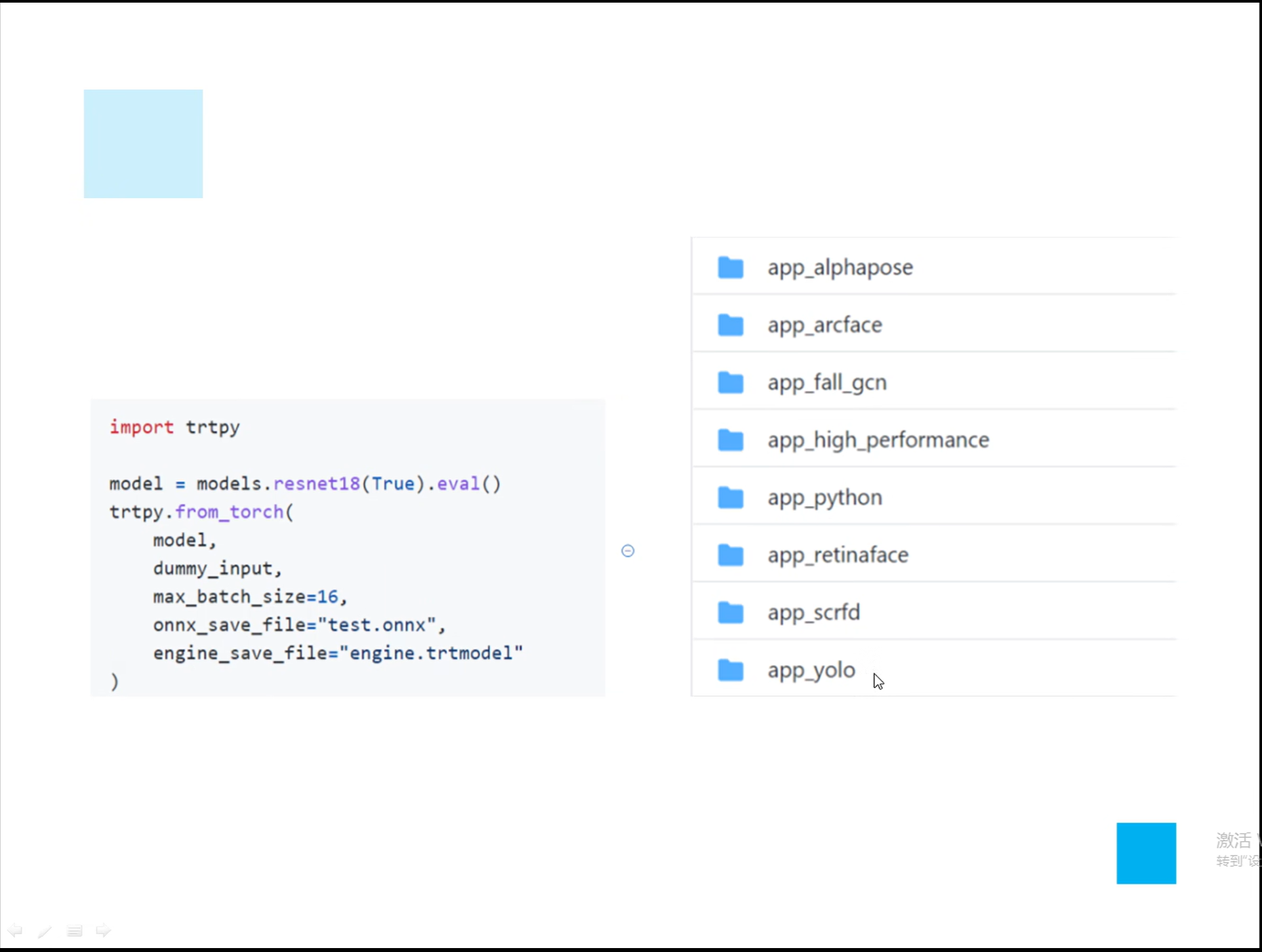
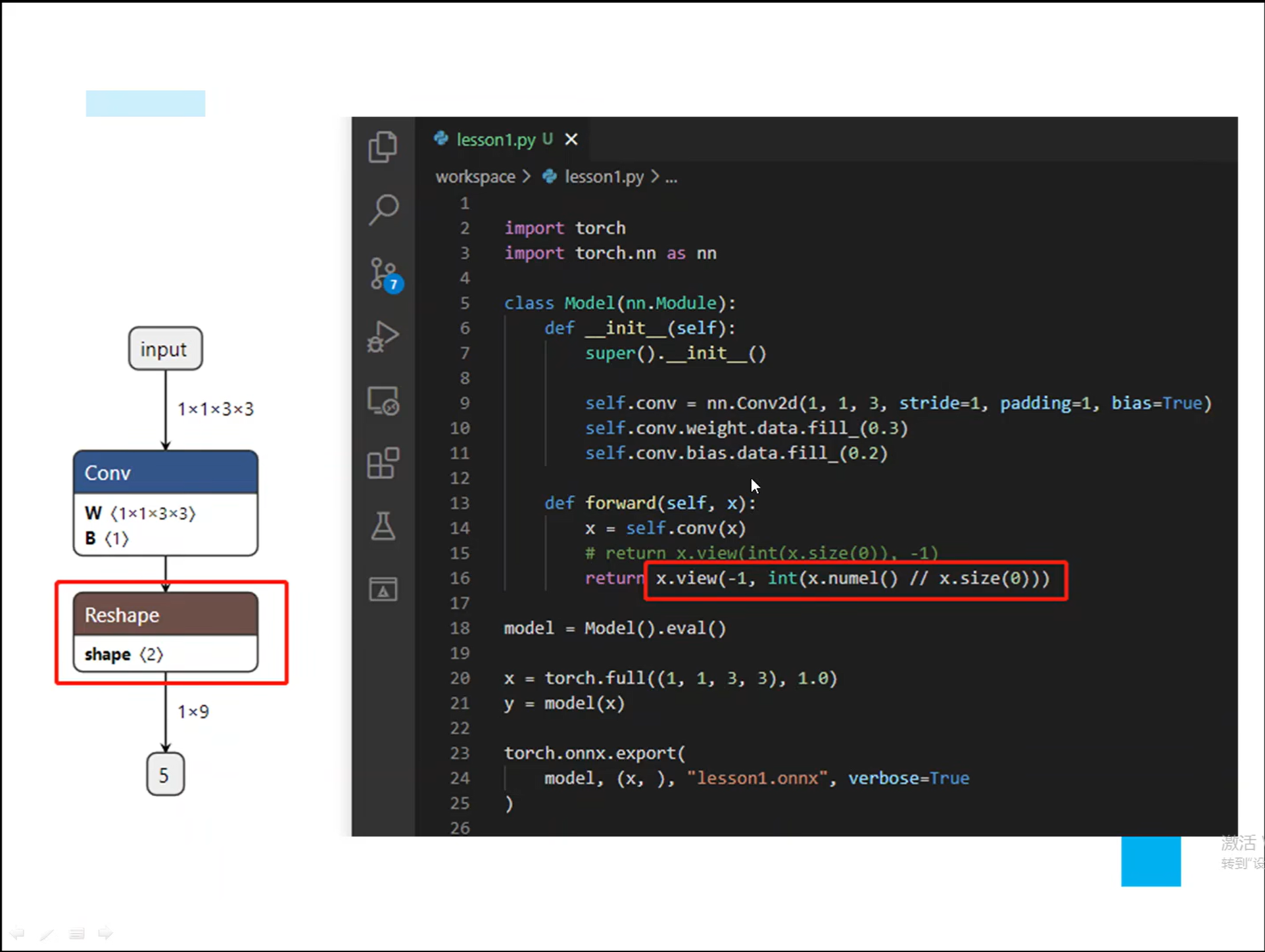
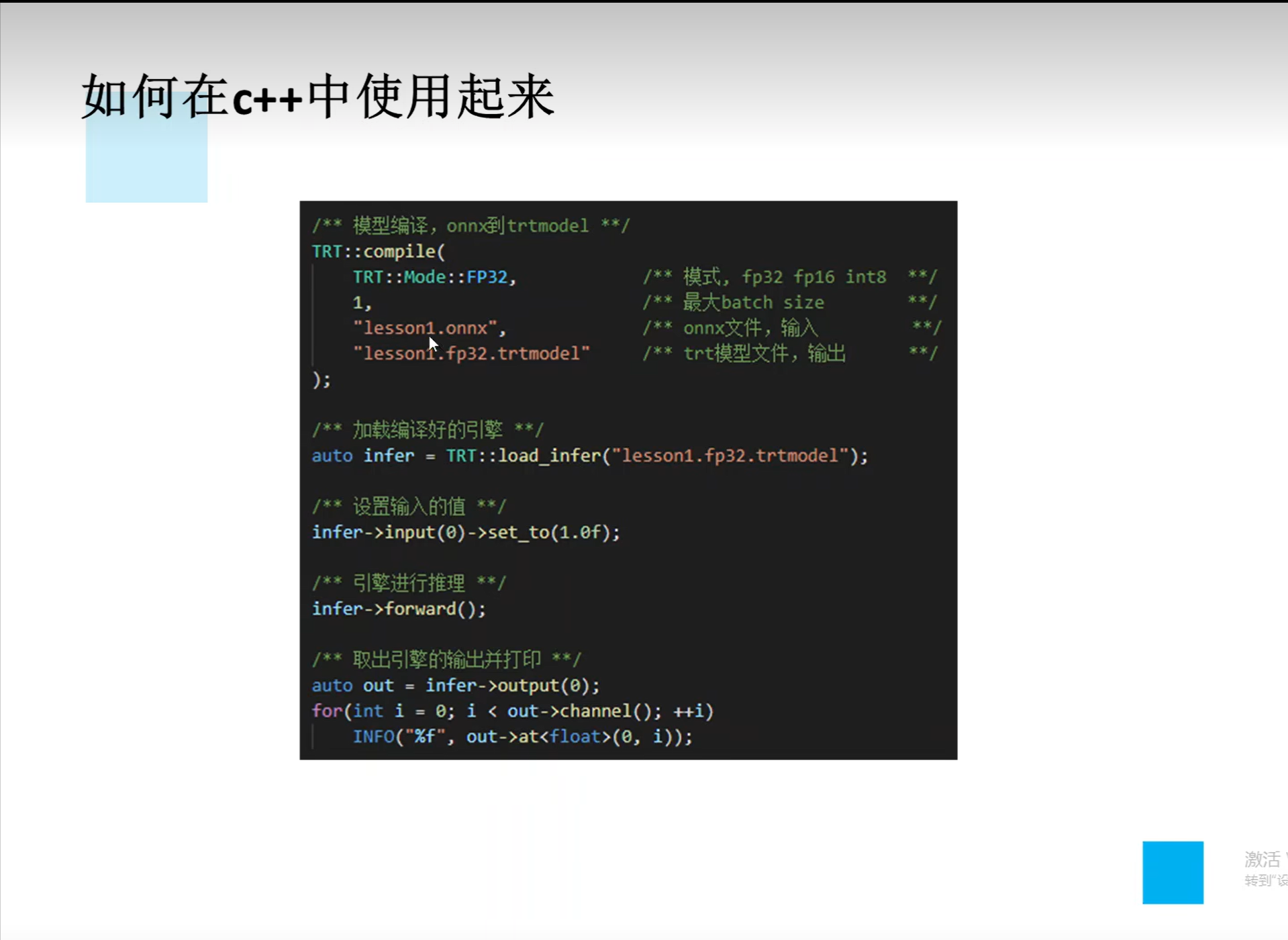
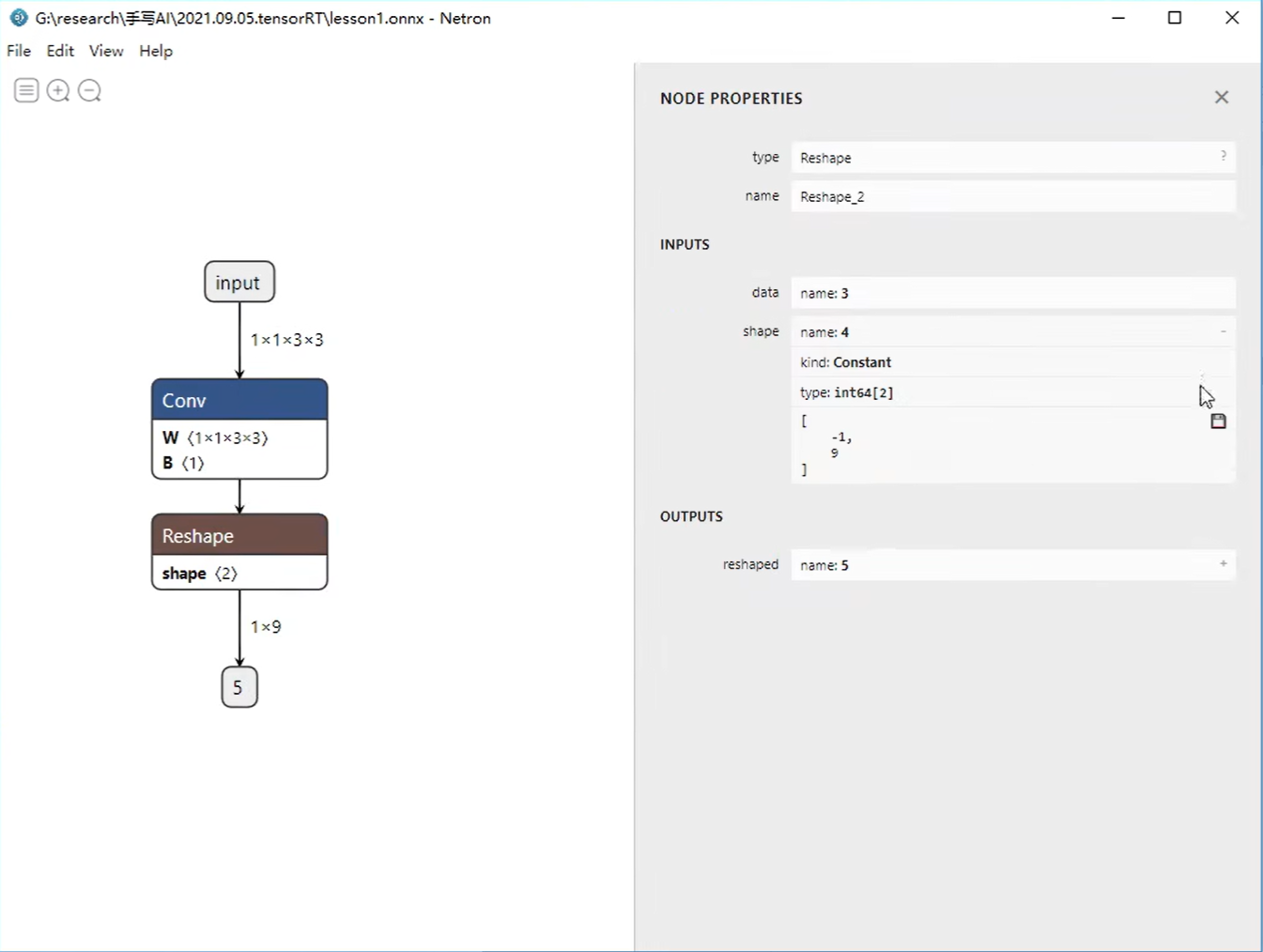
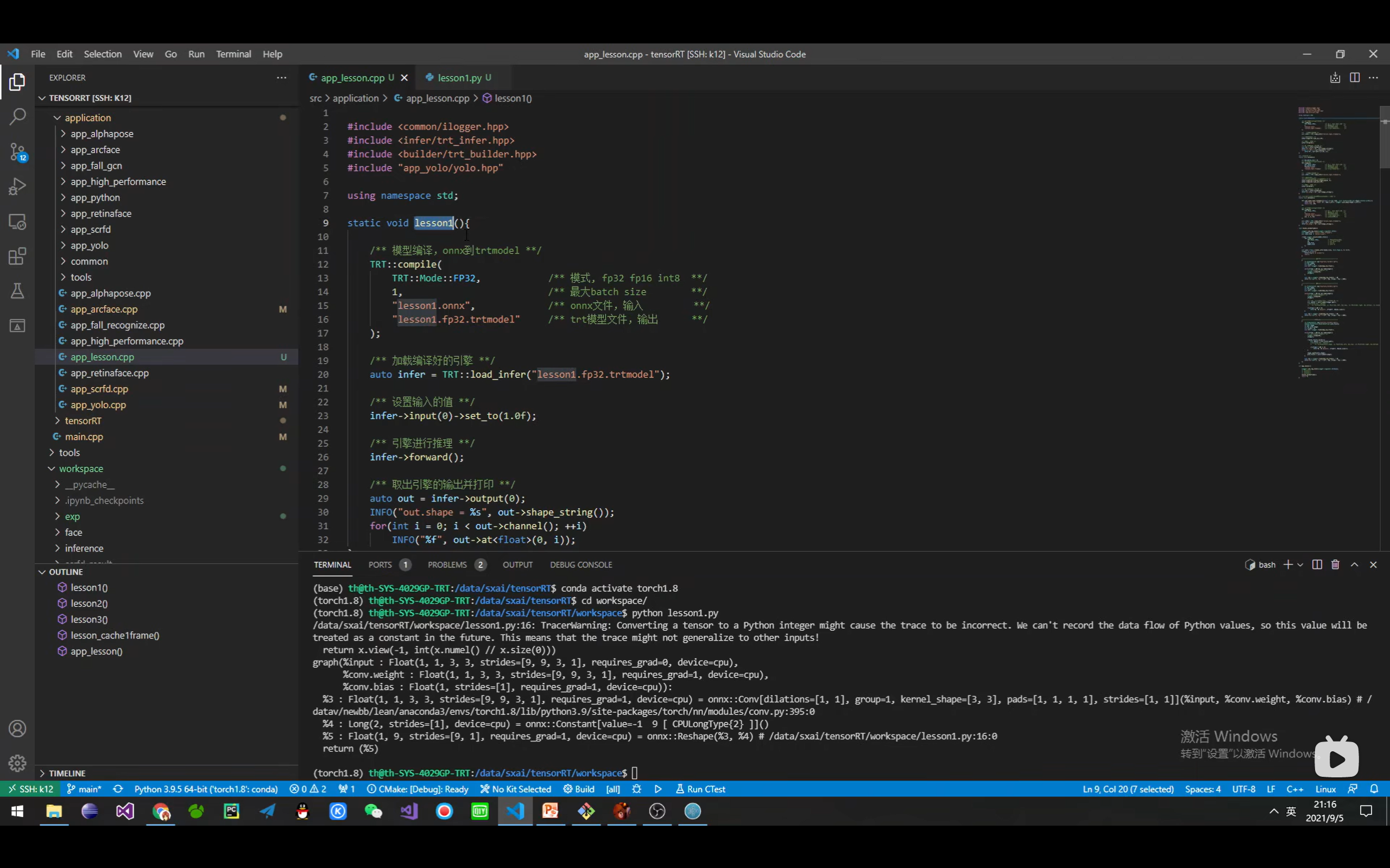
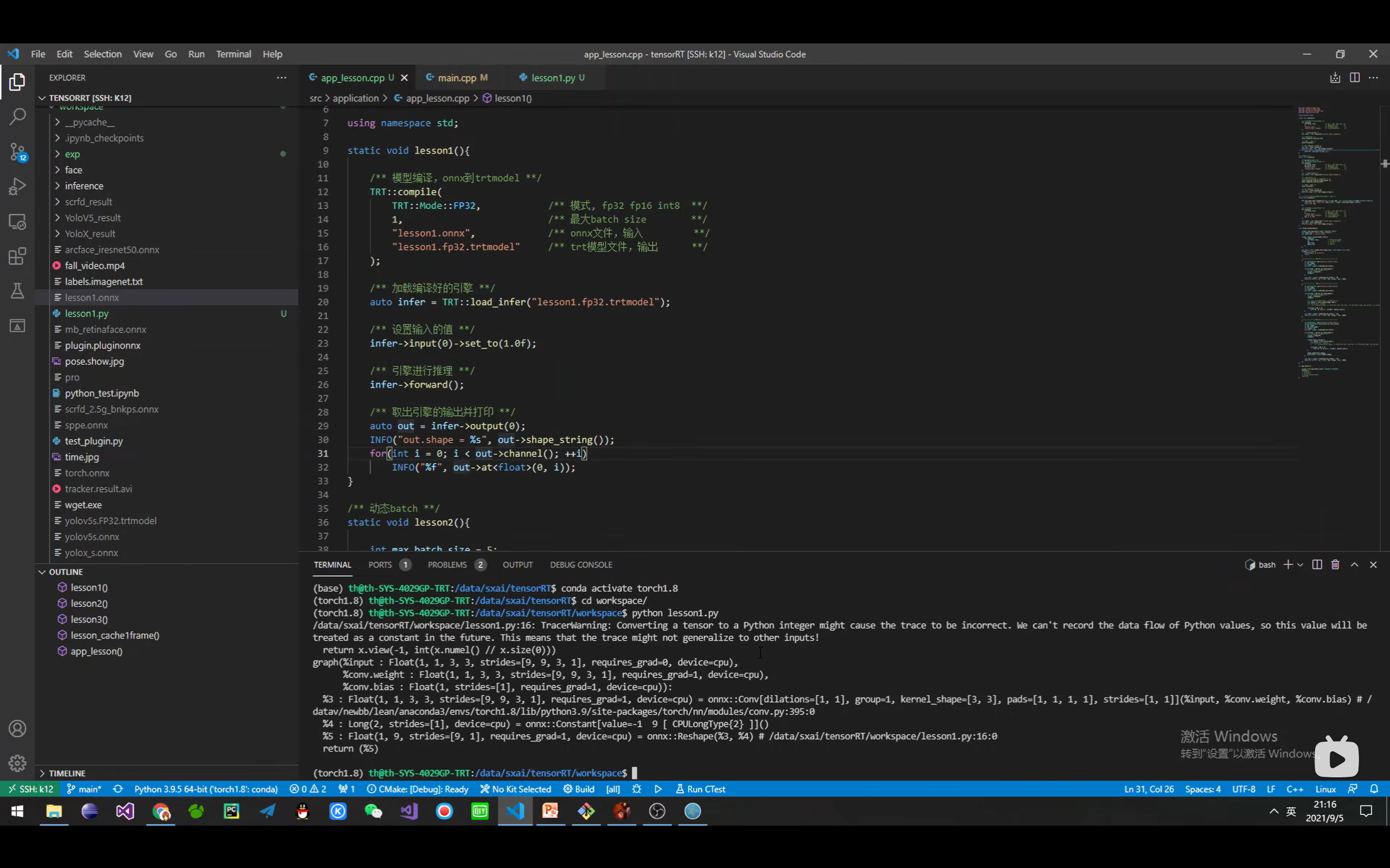
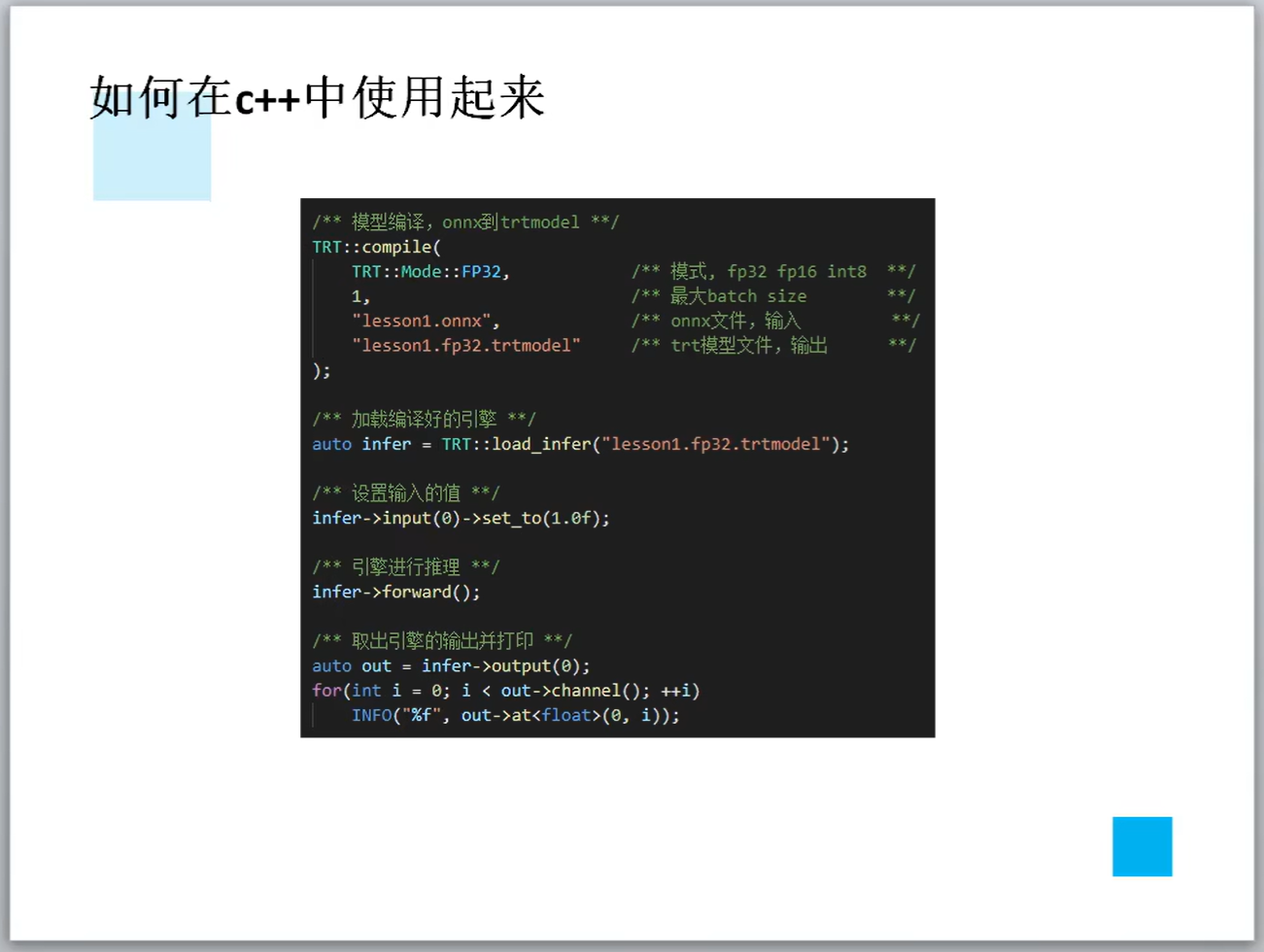
详解TensorRT的C++/Python高性能部署 发表于 2023-03-07 更新于 2023-03-16 分类于 模型部署 阅读次数: Valine: 本文字数: 184 阅读时长 ≈ 1 分钟 学习内容 要实现高性能,对于预处理和后处理要写cuda核函数; 驾驭tensorRT的方案介绍 torch2trt是由个人来维护的; 生成的trt engine是和设备绑定的,在一个型号的显卡上编译的模型不一定能在另一个显卡上好好的执行; 这种方法必须在设备上安装pytorch,然后再导出这个模型,因为从别的地方导出的模型是不一定能用的; 如何正确导出onnx并在C++中正确推理