经典网络分析

AlexNet
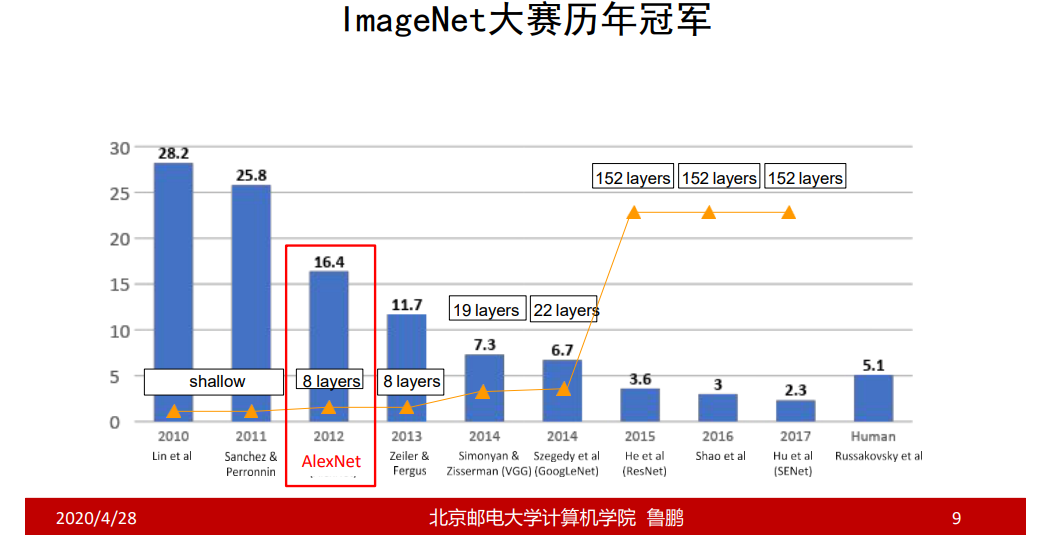
AlexNet——验证了深度卷积神经网络的高效性
主体贡献
- 提出了一种卷积层加全连接层的卷积神经网络结构;
- 首次使用ReLU函数做为神经网络的激活函数;
- 首次提出Dropout正则化来控制过拟合 ;
- 使用加入动量的小批量梯度下降算法加速了训练过程的收敛;
- 使用数据增强策略极大地抑制了训练过程的过拟合;
- 利用了GPU的并行计算能力,加速了网络的训练与推断;
结构

NORM:批量相应归一化层;(现在基本不用了,因为它的性能在更深的网络里不太明显,计算量又有点大)
Max POOL:池化层;
AlexNet是8层神经网络结构,池化层和归一化层在计算神经网络的层数时不参与计算;
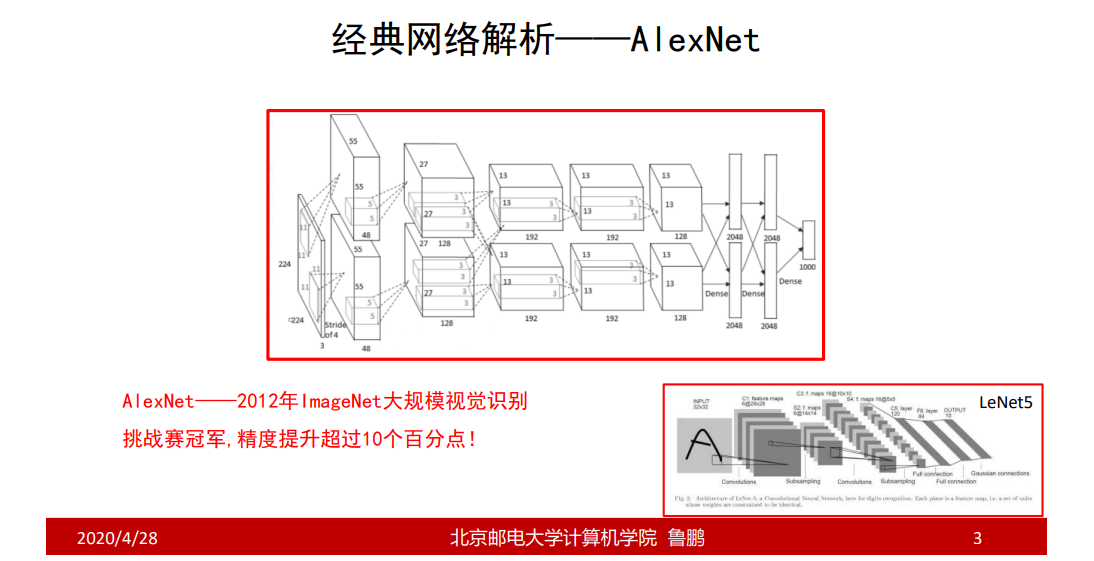
卷积层
第一个卷积层的输入是经过去均值操作 后的数据,即原始向量—均值向量,再输入到神经网络里面;
去均值的作用?
我们在分类任务中,均值向量是没有实际意义的,在向量比较时,绝对值是没有意义的,比较的相对值。去均值是为了保留自己的相对值,这样也会更加有利于计算。
池化层
3个池化层的卷积核大小3 * 3,步长为2;
这里是重叠池化,重叠有利于对抗过拟合,但是一般还是采用2*2的卷积核,步长为2;
池化层的作用:降低特征图尺寸,对抗轻微的目标偏移带来的影响;
轻微的目标偏移:比如在一个卷积核中最大值为8,最大池化后是8;但当这个8跑到这个卷积核中别的位置时,池化后的结果还是为8;因此能够对抗轻微的目标偏移带来的影响。
局部相应归一化层
目前基本不用了;
后来的研究表明: 更深的网络中该层 对分类性能的提升 效果并不明显,且 会增加计算量与存 储空间。
作用
- 对局部神经元的活动创建竞争机制; 、
- 响应比较大的值变得相对更大;
- 抑制其他反馈较小的神经元;
- 增强模型的泛化能力;
全连接层
MAX POOL3的输出:特征响应图组,大小为6 6 256;
把MAX POOL3的输出打平成9216(6 6 256)维的向量,交给全连接层;
重要说明
- 用于提取图像特征的卷积层以及用于分类的全连接层是同时学习的;
- 卷积层与全连接层在学习过程中会相互影响、相互促进;
卷积层和全连接层是一起训练的,被训练的梯度是可以回传的;
重要技巧
- Dropout策略防止过拟合;
- 使用加入动量的随机梯度下降算法,加速收敛;
- 验证集损失不下降时,手动降低10倍的学习率;
- 采用样本增强策略增加训练样本数量,防止过拟合;
- 集成多个模型,进一步提高精度(同时训练多个模型);
AlexNet卷积层在做什么

把AlexNet卷积层看作是一个卷积层,输入227 227 3,输出6 6 256,相当于有256个卷积核,获得256个特征响应图,把256个特征响应图拉成向量;
特征响应图某点处较亮,说明该亮处含有该卷积核的特征;
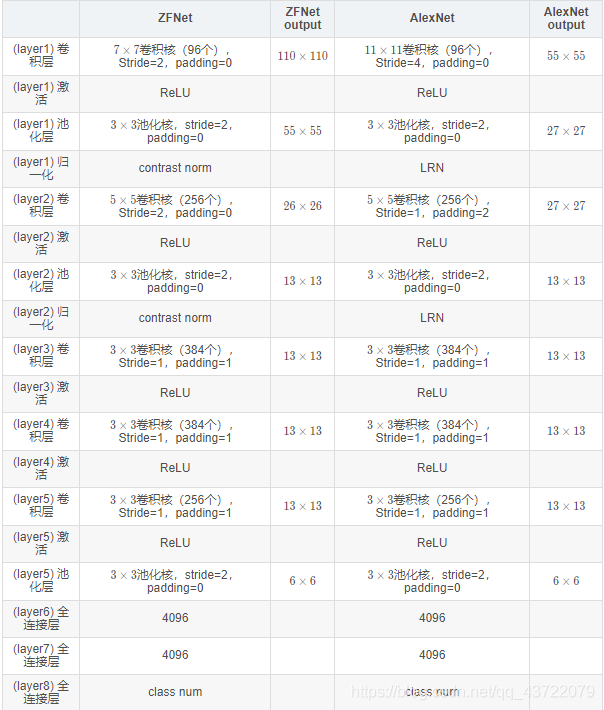
ZFNet

主体结构

主要改进
- 将第一个卷积层的卷积核大小改为了7×7;(不要一次卷积就丢掉细颗粒度的东西)
- 将第一、第二个卷积层的卷积步长都设置为2;(缓慢给图像降维)
- 增加了第三、第四个卷积层的卷积核个数;(第三层、第四层有语义信息了,增加了神经元即增加模板信息,仅仅靠现有的模板数不足以存储信息)
AlexNet与ZFNet的对比
VGG
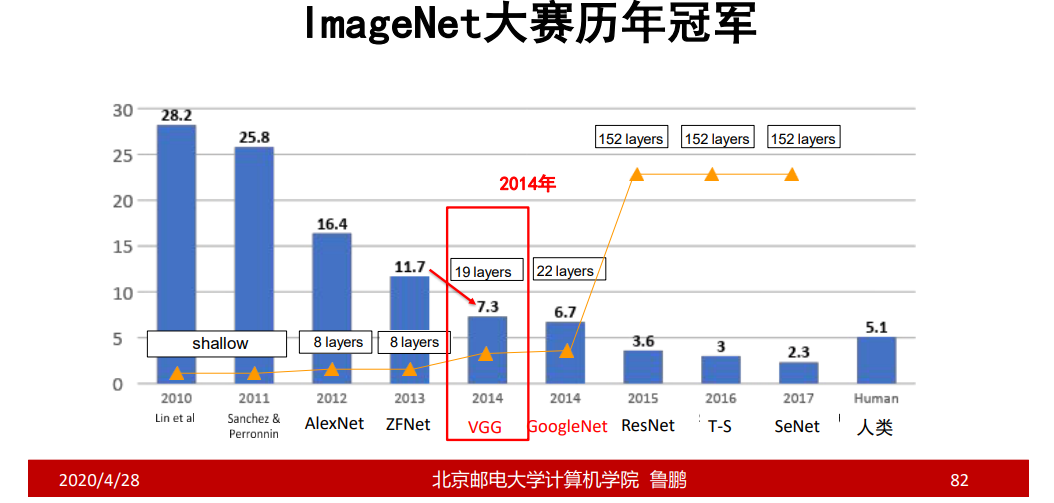
结构


VGG的输入
VGG的输入与AlexNet和ZFNet是不同的,它是先把所有的R、G、B的均值求出来,然后再进行去均值的操作。
VGG16 VS VGG19

思考
问题1:小卷积核有哪些优势?
多个小尺寸卷积核串联可以得到与大尺寸卷积核相同的感受野;
使用小卷积核串联构建的网络深度更深、非线性更强、参数也更少。
注:2个3 3卷积核的感受野相当于1个5 5卷积核的感受野;这两方式虽然感受野相同,但是最后获取的结果可能是不同的。
问题2::为什么VGG网络前四段里,每经过一次池化操作,卷积核个数就增加一倍?
池化操作可以减小特征图尺寸,降低显存占用;
增加卷积核个数有助于学习更多的结构特征,但会增加网络参数数量以及内存消耗;
一减一增的设计平衡了识别精度与存储、计算开销;
最终还是提升了性能
问题3:为什么卷积核个数增加到512后就不再增加了?
- 第一个全连接层含102M参数,占总参数个数的74%;
- 这一层的参数个数是特征图的尺寸与个数的乘积;
- 参数过多容易过拟合,且不易被训练;
注:第一层全连接层的输入为7 7 512维的向量,则这一层需要的参数为102M(7 7 512 * 4096)参数;
若继续增加卷积核个数,那么第一层全连接层参数会更多,如为1024个卷积核,那么第一层全连接层参数将为200M,那样模型将会很难被训练;因此不是不想增加,而是增加不了。
GoogleNet

GoogleNet的结构


GoogleNet的创新点
- 提出了一种Inception结构,它能保留输入信号中的更多特征信息;
- 去掉了AlexNet的前两个全连接层,并采用了平均池化,这一设计使得 GoogLeNet只有500万参数,比AlexNet少了12倍;
- 在网络的中部引入了辅助分类器,克服了训练过程中的梯度消失问题;
从AlexNet等一些经典的神经网络中可知参数极大多数来源于与最后一层卷积层相连接的第一层全连接层,当在GoogleNet中最后一层卷积层后采用平均池化的方法,大大降低了第一层全连接层的参数;
串联结构(如VGG)存在的问题
后面的卷积层只能处理 前层输出的特征图;前层丢失重要信息,后层无法找回。
解决方案:
—每一层尽量多的保留输入信号中的信息。
Inception模块和Inception V1模块
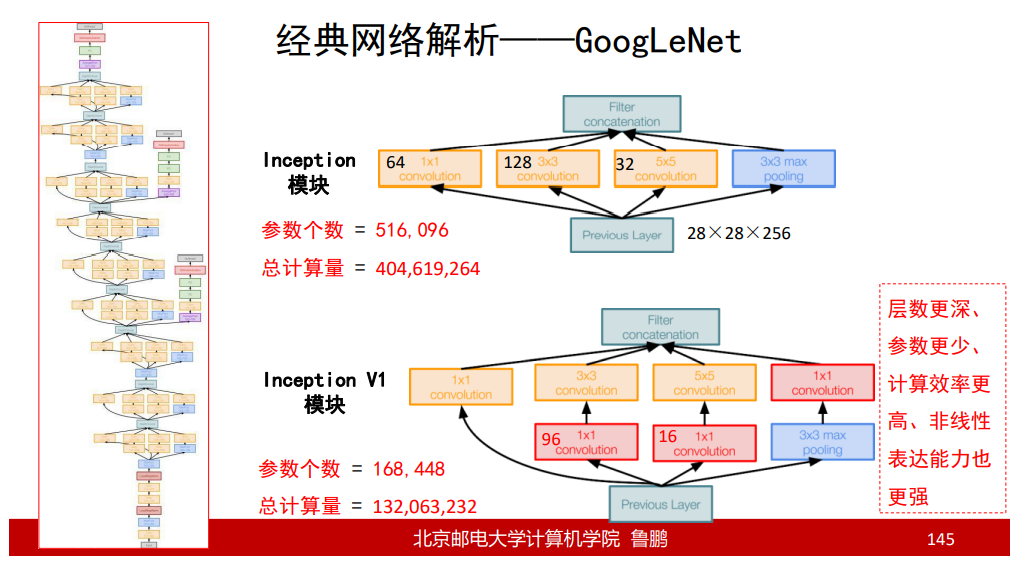
1 * 1 conv:把原来的信息进行压缩整理;
3 3 conv:提取3 3的局部特征;
5 5 conv:提取5 5的局部特征;
1 * 1 max pooling:提取扩张以后的信息;(max pooling相当于最大化抑制,max pooling对周围信息进行了扩展,比如一片区域内最大值是9,那么经过max pooling后,9的周围就会都变成9,对9这个信号进行加强)
为了保证输出的特征图大小相同,分别对1 1,3 3,5 * 5这3个卷积层进行边缘进行0,1,2的零填充;
Inception模块 VS Inception V1模块
Inception V1模块增加了3个1 * 1的卷积层,使特征图的深度极大的降低,较少了参数个数和计算量,提高了效率;
1 * 1的卷积核不改变H和W,但是可以降低通道深度;
GoogleNet的总结
输入
输入为去均值后224 * 224的图像,去均值采用的方法是R、G、B;
平均池化
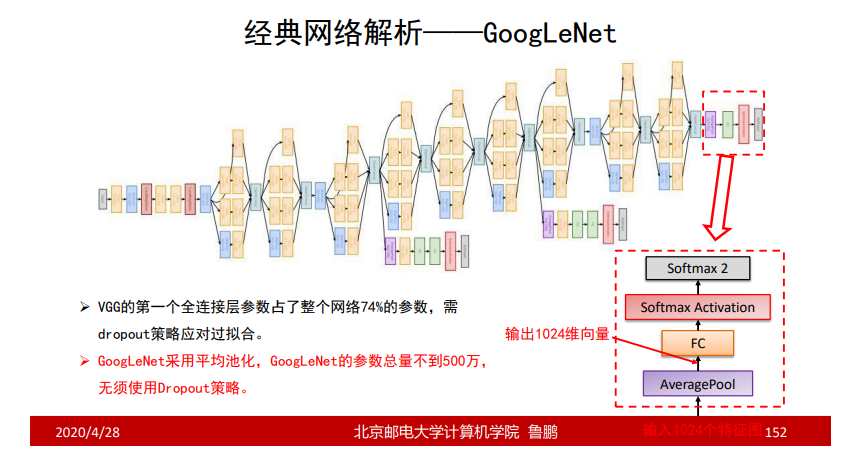
与全连接层相连时,采用的池化是平均池化;
辅助分类器损失

问题
平均池化向量化与直接展开向量化有什么区别?
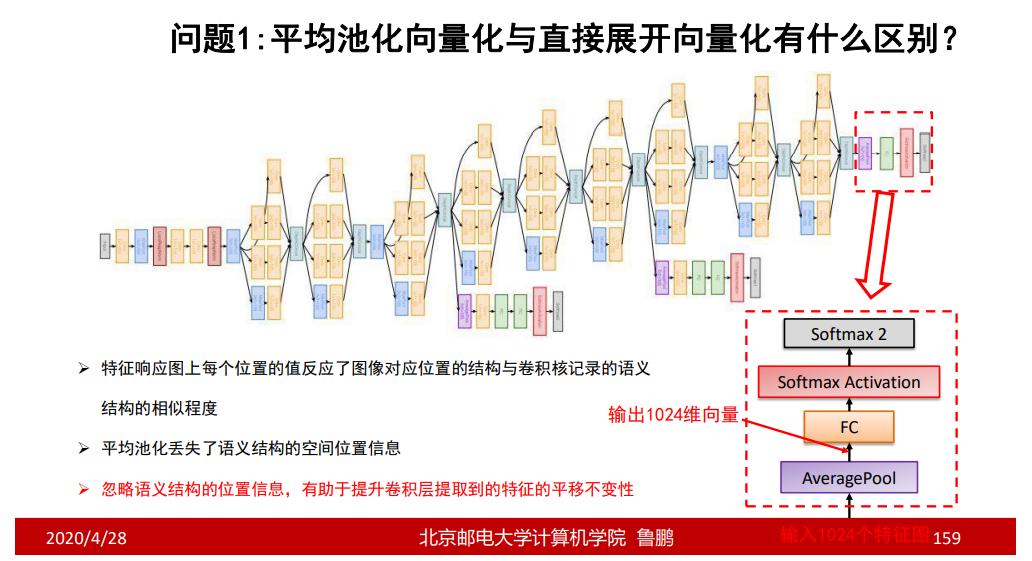
平移不变性:图像中的目标,不管被移动到图片的哪个位置,得到的结果应该是相同的,这就是卷积神经网络的平移不变性。
利用1x1卷积进行压缩会损失信息吗?
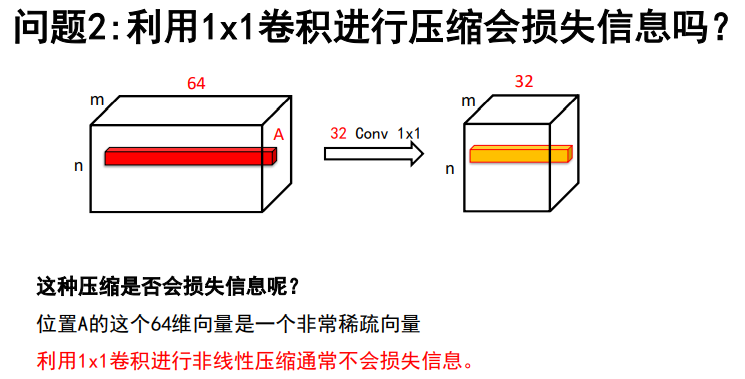
因为一个图像经过卷积核后,只有满足卷积核特征的地方值才会很大,其余基本上为0;又因为一个图像上满足某一特征的地方往往又很少,因此得到的特征向量图是十分稀疏的,经过压缩往往是压缩了大量的0,因此非线性压缩通常不会损失信息。
ResNet

问题引入

通过前面四种网络的学习,我们几乎可以想到越深层次的网络的学习效果越好;但是其实并不是这样的,当网络较深时,就会出现正反向信息流动不顺畅的问题,ResNet的出现解决了这个问题。
ResNet的贡献

ResNet残差模块

- 通过公式我们可以看出,即使F(x)不起作用,H(x)还是x的值,从而可以知道F(x)即使不起作用也不会造成负面影响;
- 原图+细节=锐化;可以理解为F(x)为提取的细节,使x得到了锐化即H(x),当H(x)作为输入时,即可以提取原图中的特征,也可以在上一层提取的细节上进行增强,因此这个前向传播信号也是不容易衰减的;
- 反向传播时,即使F(x)内梯度为0,x梯度恒为1,也能够使梯度进行回传,保证了反向梯度的通畅;
- F(x)=H(x)-X,即残差=输出-输入;输出和输入的差异叫做残差,也因此叫残差模型;

第一个Conv 1 * 1的作用:降低通道数,使能够减少参数和计算量;
第二个Conv 1 * 1的作用:增加通道数,使能够和X相加;
ResNet结构

问题
为什么残差网络性能那么好?
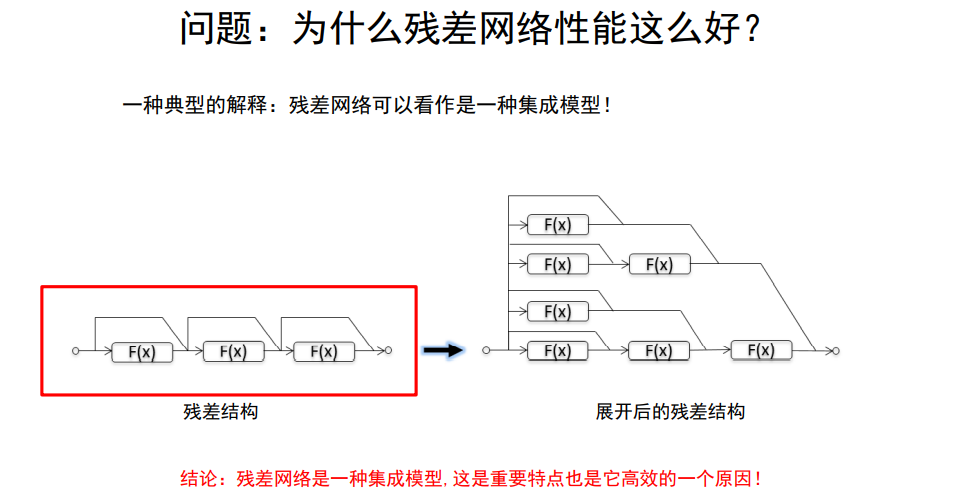
普通网络当某一层失去作用时,可能就会瘫痪,而残差网络不用这样;
残差网络会自动适应选择某些层进行工作;
总结
- 介绍了5种经典的卷积神经网络AlexNet、ZFNet、VGG、GoogLeNet和ResNet;
- 残差网络和Inception V4是公认的推广性能最好的两个分类模型;
- 特殊应用环境下的模型:面向有限存储资源的SqueezeNet以及面向有限计算资源的 MobileNet和ShuffleNet;