YOLOv1
训练阶段
图片处理成大小为448*448,喂给神经网络模型;
经过神经网络后,会输出7 7 30大小的矩阵;

30是指每个grid cell可以预测出两个bbox,每个bbox会有四个参数来表示这个bbox具体的位置和大小,每个框还有一个confidence score参数,共10个参数;另外,每个gird cell可以预测出20个类别的概率,共20个参数;共30个参数;
(x1,y1,w1,h1,confidence1,x2,y2,h2,w2,confidence2,…)(x, y)坐标代表bbox的中心相对于网格单元的边界;w,h是相对于整个图像的预测。
一个标记框的中心点落在哪个grid cell中,就让哪个gird cell的一个bbox(IOU较大)去拟合这个框,并且这个grid cell输出的类别也应该是正确的类别;
每个grid cell只能预测出一个物体,49个grid cell只能预测出49个物体;这也是YOLO v1在预测小目标和密集目标较差的原因;
在训练过程中confidence score参数是 IOU和Pr(Object)的乘积,Pr(Object)是指bbox是否是被选中的预测框的概率,非0即1;IOU是某个gird cell的bbox和打标的真是框的面积交并比;
每个grid cell预测出的两个bbox,则会产生两个IOU;若该grid cell有预测物体,则选择IOU较大的bbox去拟合;若该grid cell没有预测物体,则confidence score尽可能的小,接近于0;
最后一层预测类概率和边界框坐标。我们根据图像的宽度和高度使边界框的宽度和高度标准化,使它们在0和1之间。我们将边界盒和坐标参数化,使其成为特定网格单元格位置的偏移量,因此它们也被限定在0和1之间。
损失函数的设计:

- 带^的数据是真实值;
- λcoord和λnoobj的作用是为了平衡负样本和正样本比例不均衡的问题;
- Ci的标签值非0即1;
- pi的标签值非0即1;
- 对于中心点的损失直接用了均方误差,但是对于宽高为什么用了平方根呢?
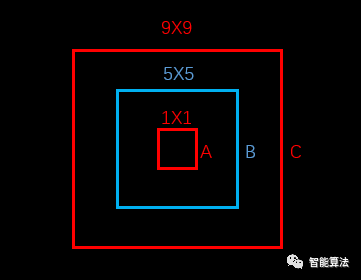
上图中,蓝色为bounding box,红色框为真实标注,如果W和h没有平方根的话,那么bounding box跟两个真实标注的位置loss是相同的。但是从面积看来B框是A框的25倍,C框是B框的81/25倍。B框跟A框的大小偏差更大,所以不应该有相同的loss。
如果W和h加上平方根,那么B对A的位置loss约为3.06,B对C的位置loss约为1.17,B对A的位置loss的值更大,这更加符合我们的实际判断。所以,算法对位置损失中的宽高损失加上了平方根。(参考于https://blog.csdn.net/x454045816/article/details/107527326/)
因为平方根对小数据敏感,对大数据不敏感,比如对于根号x,一阶导数随着x的增大而减小
预测阶段
直接把图片交给神经网络即可输出结果;
采用NMS非极大值抑制的方法,使低置信度的预测不显示出来;
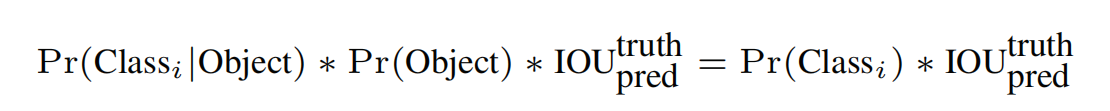
并不是所有的gird cell的都可以预测出物体的位置;
(参考于https://blog.csdn.net/weixin_48200452/article/details/116453893)