面试[2022.4.25]

在缺少有效预防欠拟合和过拟合措施的情况下,随着模型拟合能力的增强,错误率在训练集上逐渐减小,而在验证集上先减小后增大;当两者的误差率都较大时,处于欠拟合状态(high bias, low variance);当验证集误差率达到最低点时,说明拟合效果最好,由最低点增大时,处与过拟合状态(high variance, low bias)。(参考于https://blog.csdn.net/txpp520/article/details/105347189)
在缺少有效预防欠拟合和过拟合措施的情况下,随着模型拟合能力的增强,错误率在训练集上逐渐减小,而在验证集上先减小后增大;当两者的误差率都较大时,处于欠拟合状态(high bias, low variance);当验证集误差率达到最低点时,说明拟合效果最好,由最低点增大时,处与过拟合状态(high variance, low bias)。(参考于https://blog.csdn.net/txpp520/article/details/105347189)

查准率:就是预测是真的中,实际是真的的比例;
查全率:就是标签是真的中,预测是真的的比例;
| 预测真 | 预测假 | |
|---|---|---|
| 标签真 | TP | FN |
| 标签假 | FP | TN |
T/F:True/False;
P/N:Positive/Negative
Precision(查准率或精确率) = TP / (TP+FP)
Recall(查全率或召回率) = TP / (TP+FN)

IOU就是预测框和真实框两则的交集和并集的比值;
confidence表示它是一个物体的可能性有多大;
map指标综合衡量检测效果;

求AP值首先需要设定一个IOU阈值,按照置信度的大小对所有的预测框进行排序;
然后分别按照每个置信度的值为阈值求出P和R,有多少个预测框就有多少对P、R值(P、R值可能会相同);
把P-R值绘制到P-R图像上面;
对PR曲线进行平滑处理,即对PR曲线上的每个点,Precision的值取该点右侧最大的Precision的值;
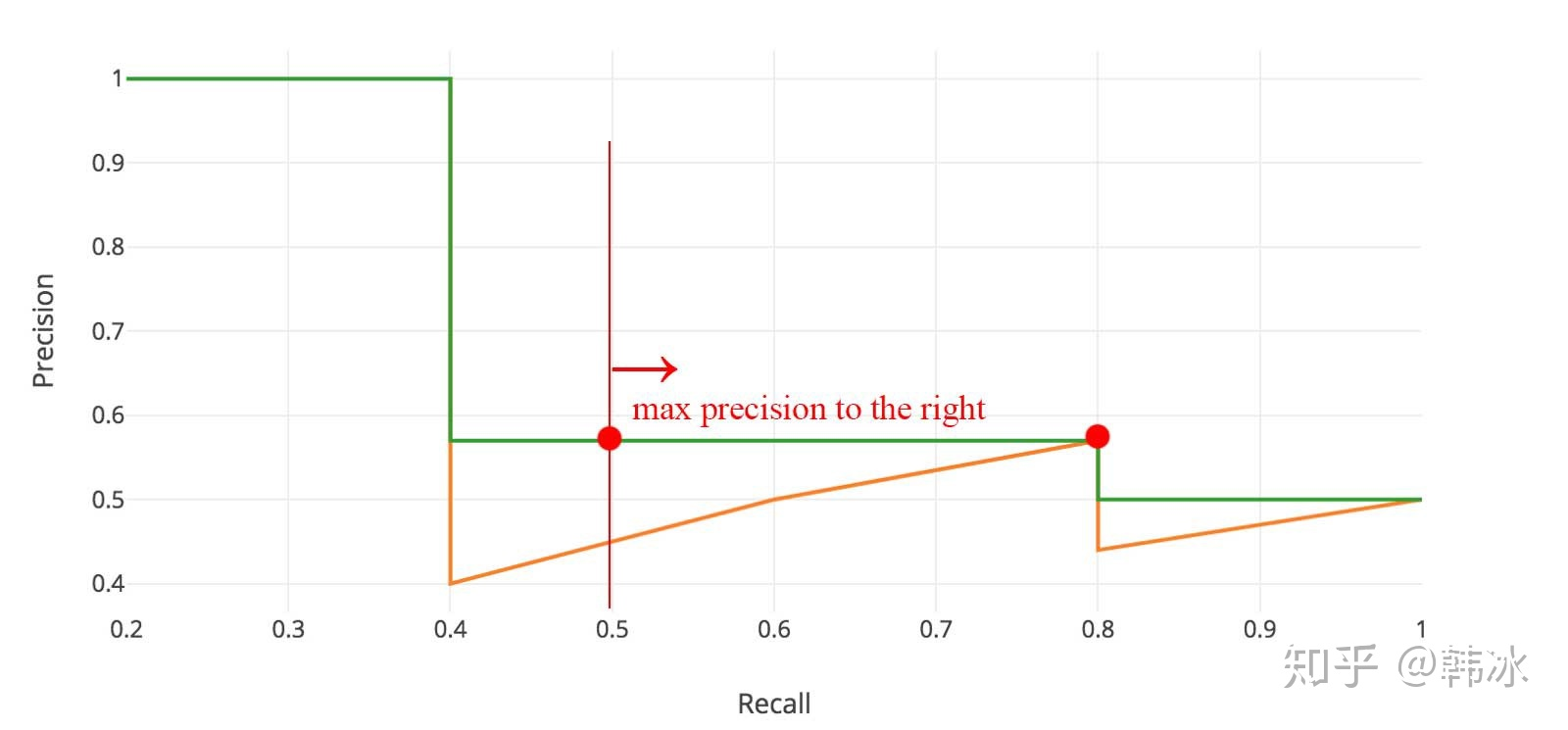
求出PR曲线平滑后围成图形的面积,即为AP值;
求出各个类的AP,然后求平均,即为mAP(通常来说AP是在单个类别下的,mAP是AP值在所有类别下的均值);
1 | import os |
1 | import numpy as np |
小王子遇见了一只狐狸。狐狸告诉小王子,“如果你驯服我,我们便属于彼此。”
小王子每天在同一个时间来,渐渐地他驯服了狐狸。
可是小王子却要离开了。
在小王子要离开的时候,狐狸让他再去看一眼那五千多朵玫瑰。
小王子回到了玫瑰园。
他对玫瑰们说,“你们很美丽,但也很空虚,不会有人为你们去死。当然,寻常的路人会认为我的玫瑰花和你们差不多。但她比你们全部加起来还重要,因为我给她浇过水。因为我给她盖过玻璃罩。因为我为她挡过风。因为我为她消灭过毛毛虫。因为我倾听过她的抱怨和吹嘘,甚至有时候也倾听她的沉默。因为她是我的玫瑰。“
小王子最后与狐狸告了别。
狐狸告诉了小王子一个秘密:”你的玫瑰之所以如此宝贵,是因为你曾为她付出的时间。“
图片处理成大小为448*448,喂给神经网络模型;
经过神经网络后,会输出7 7 30大小的矩阵;

30是指每个grid cell可以预测出两个bbox,每个bbox会有四个参数来表示这个bbox具体的位置和大小,每个框还有一个confidence score参数,共10个参数;另外,每个gird cell可以预测出20个类别的概率,共20个参数;共30个参数;
(x1,y1,w1,h1,confidence1,x2,y2,h2,w2,confidence2,…)
(x, y)坐标代表bbox的中心相对于网格单元的边界;w,h是相对于整个图像的预测。
一个标记框的中心点落在哪个grid cell中,就让哪个gird cell的一个bbox(IOU较大)去拟合这个框,并且这个grid cell输出的类别也应该是正确的类别;
每个grid cell只能预测出一个物体,49个grid cell只能预测出49个物体;这也是YOLO v1在预测小目标和密集目标较差的原因;
在训练过程中confidence score参数是 IOU和Pr(Object)的乘积,Pr(Object)是指bbox是否是被选中的预测框的概率,非0即1;IOU是某个gird cell的bbox和打标的真是框的面积交并比;
每个grid cell预测出的两个bbox,则会产生两个IOU;若该grid cell有预测物体,则选择IOU较大的bbox去拟合;若该grid cell没有预测物体,则confidence score尽可能的小,接近于0;
最后一层预测类概率和边界框坐标。我们根据图像的宽度和高度使边界框的宽度和高度标准化,使它们在0和1之间。我们将边界盒和坐标参数化,使其成为特定网格单元格位置的偏移量,因此它们也被限定在0和1之间。
损失函数的设计:

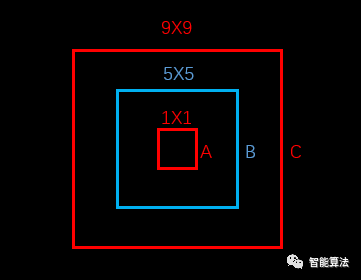
上图中,蓝色为bounding box,红色框为真实标注,如果W和h没有平方根的话,那么bounding box跟两个真实标注的位置loss是相同的。但是从面积看来B框是A框的25倍,C框是B框的81/25倍。B框跟A框的大小偏差更大,所以不应该有相同的loss。
如果W和h加上平方根,那么B对A的位置loss约为3.06,B对C的位置loss约为1.17,B对A的位置loss的值更大,这更加符合我们的实际判断。所以,算法对位置损失中的宽高损失加上了平方根。(参考于https://blog.csdn.net/x454045816/article/details/107527326/)
因为平方根对小数据敏感,对大数据不敏感,比如对于根号x,一阶导数随着x的增大而减小
直接把图片交给神经网络即可输出结果;
采用NMS非极大值抑制的方法,使低置信度的预测不显示出来;
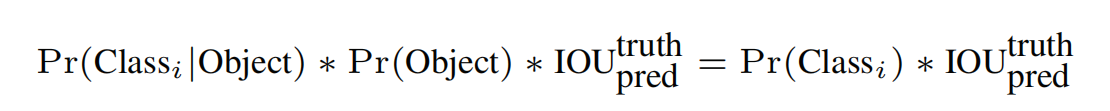
并不是所有的gird cell的都可以预测出物体的位置;
(参考于https://blog.csdn.net/weixin_48200452/article/details/116453893)
直接对矩阵进行转置;
1 | array([[0, 1], |
交换x,y时:
1 | A = array([[[ 0, 1, 2, 3], |
np.transpose(img, (1, 0, 2))操作,可以将图像逆时针翻转90度

实例分割与语义分割不同的是:语义分割只区分同一种类,不区分同一种类中的不同。
给每个像素分配类别标签不区分实例,只考虑像素类别。
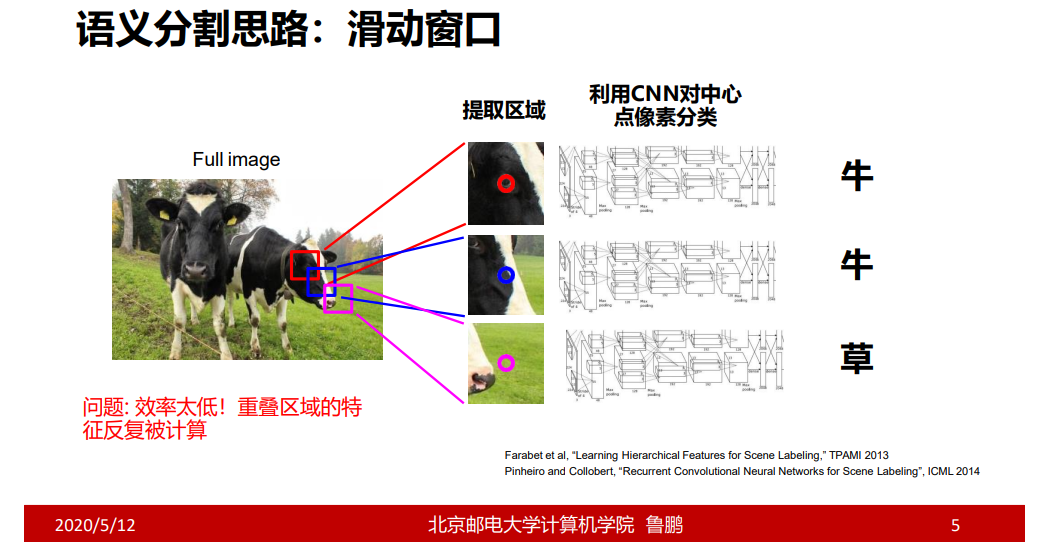
具体过程:在一张图片上,通过滑动窗口的方式对每个点取周围的区域进行分类判断;
存在的问题:效率太低;
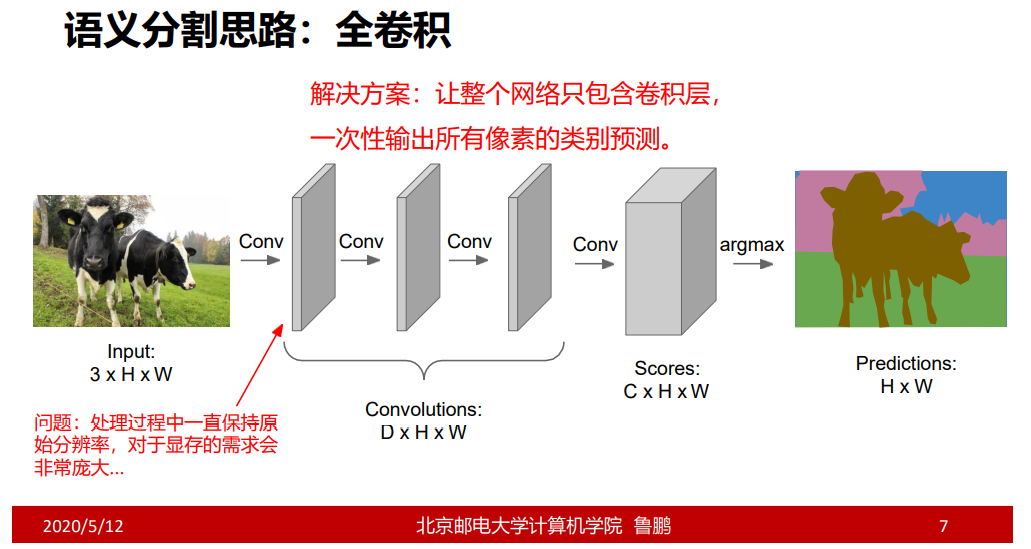
C的大小为类别个数;
具体过程:给输入的特征图增加padding,使其保持原有大小;输出为C H w的特征图,可以看成H W个C维向量,每个C维向量只有一个类别;并且把标答也做成C H * W,利用交叉熵进行比较,并进行反向传播;
但同时也存在问题;

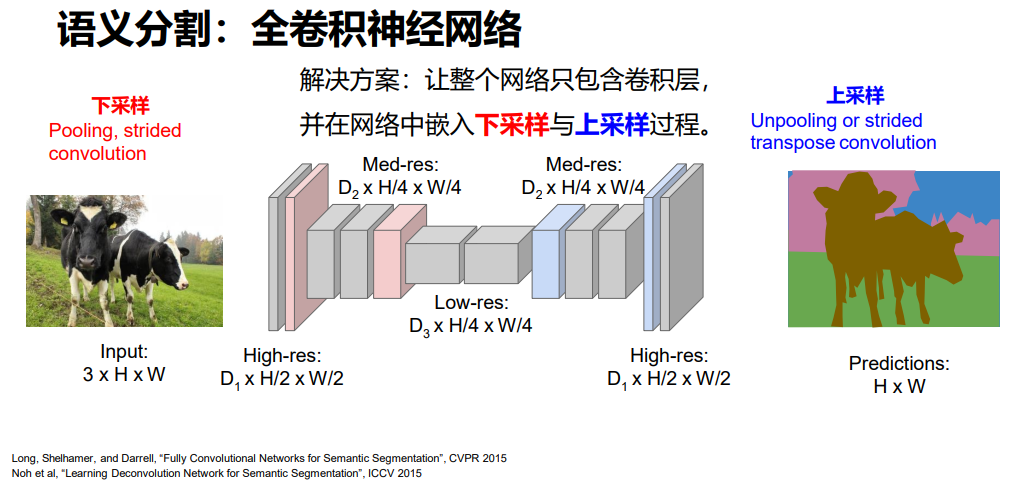
下采样可以通过padding或增大步长的方式实现;
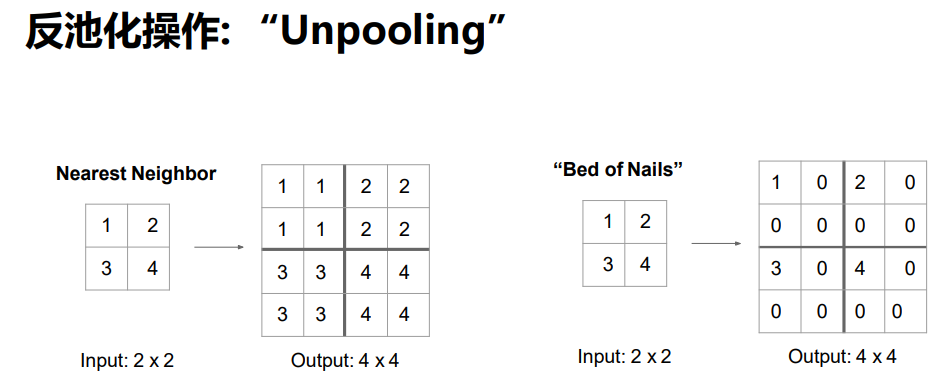
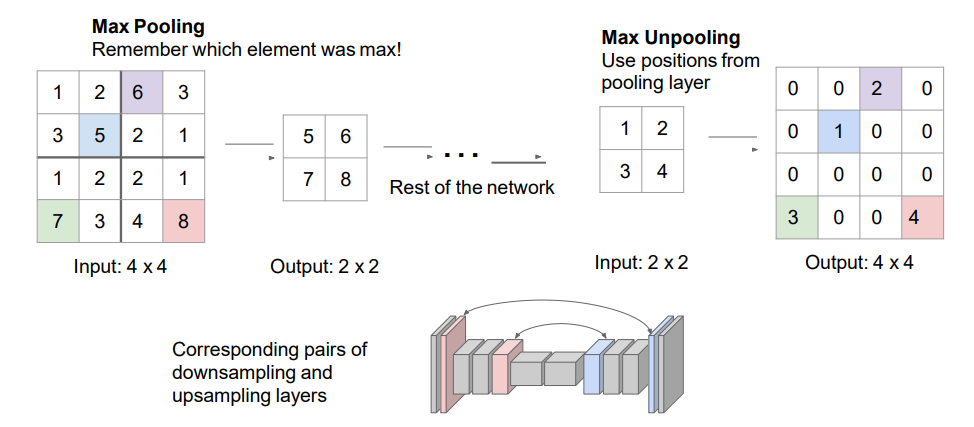
把1,2,3,4放到5,6,7,8的位置;
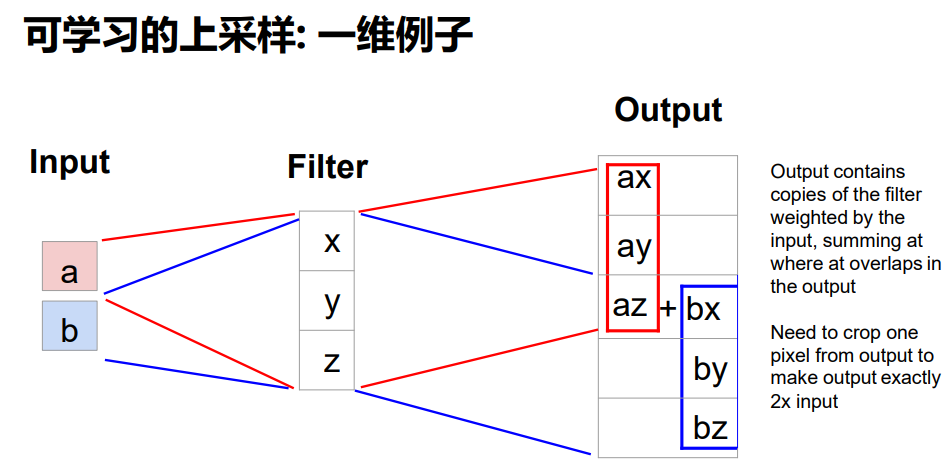
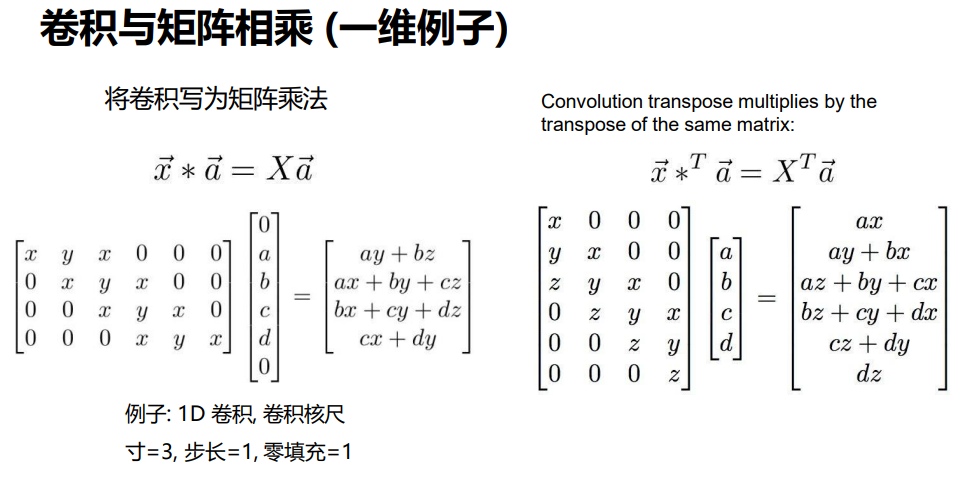
x,y,z是三个参数;左右两图的两组x,y,z参数是不同的;
不光告诉我们图像中有什么目标,还要告诉我们它在什么位置;
在倒数第二层的全连接层上分别接上分类器和确定位置的神经网络;
当做目标定位这种网络时,找到一个预先训练好的模型,然后直接把它分类,然后在这个训练的基础上,训练倒数第二层与定位层直接连接的参数,让它的总损失降到最低;
在实际的训练过程中可以这样,先训练好分类,然后所有参数不变去训练定位层的参数,然后再把所有参数都打开进行微调,使总损失下降;
因为有分类和定位,所有又称多任务损失;
分类的损失很容易计算,那么定位的损失如何计算呢?
x,y,h,w相差的平方和。
在计算两个损失和时,可以设置权重,来倾向于哪个更拟合正确;
当多个目标时,就难以知道标答的计算,采用单目标分类定位的方法是不可行的;只有当目标个数确定时,才能用单目标这种方法进行;
即因为不知道目标的个数,就难以确定输出的维度;
存在的问题:CNN需要对图像中所有可能的区域(不同 位置、尺寸、长宽比)进行分类,计算量巨大!

利用区域建议方法产生感兴趣的区域,并对该区域进行缩放到224 224,因为输入要求是224 224,然后再把缩放后的图像进行特征提取;随后进行Bbox reg进行坐标回归和使用支持向量机对区域进行分类;
通过Bbox reg回归选取和实际的误差,调节选取窗口的参数,解决了选取区域不准确的问题;
存在的问题:计算效率低下;
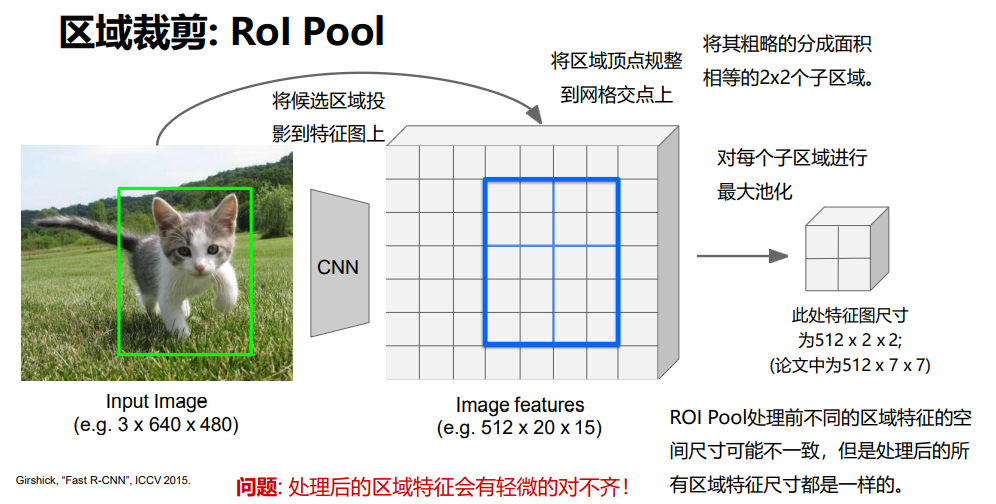
解决方法:在特征图上进行区域扣取;

先对整图进行卷积操作,然后再进行区域裁剪和缩放特征;
要保证裁剪和缩放都可导,整个网络才能训练。
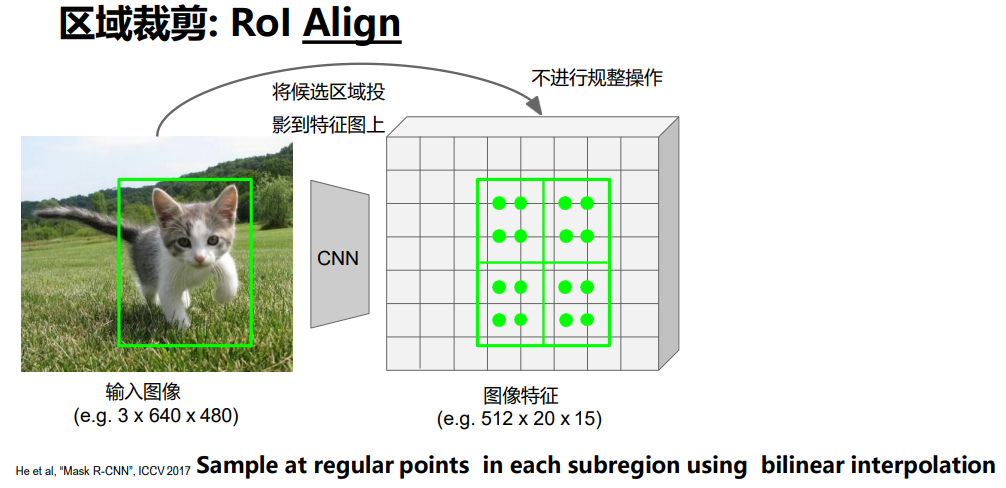
与Rol Pool相比,保持映射过来的区域,平均选取四个点,进行计算该点的值,再采用最大池化的方式进行提取;
如何计算选点处的值?
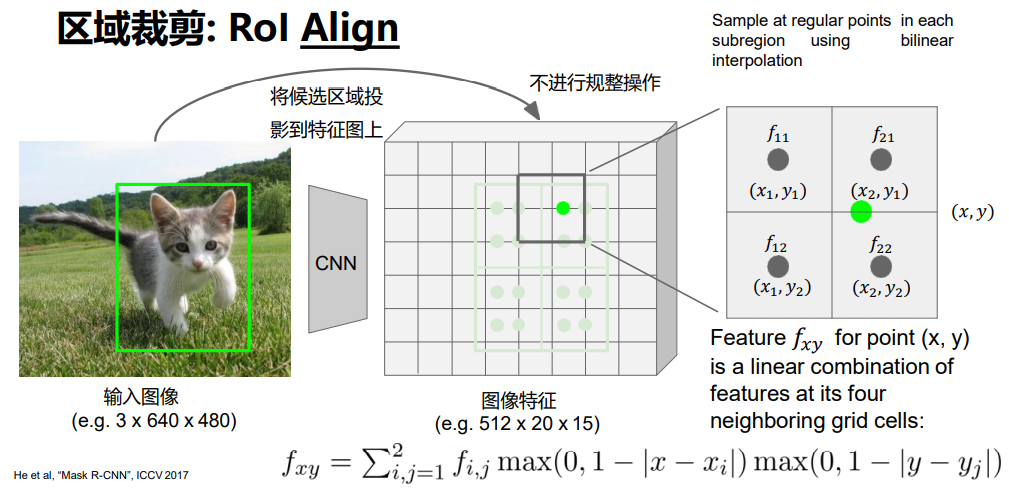

在中间特征层后加入区域建议网络RPN( Region Proposal Network) 产生候选区域,其他部分保持与Fast R-CNN一致,即 扣取每个候选区域的特征,然后对其进行分类。

对每一个像素都要在它外面圈一个框,这个框的分类是什么,这代表这个位置的分类就是什么(是不是目标);
问题:框选取多大,框长什么样?
在编程的时候选取的都是固定的区域,但是可以通过回归出来和真正需要选择区域的偏差量,调整区域框;
4k的4:每个像素回归4个数字;
对于选取的K 20 15 的边框,选取最合适的前300个边框进行目标检测;
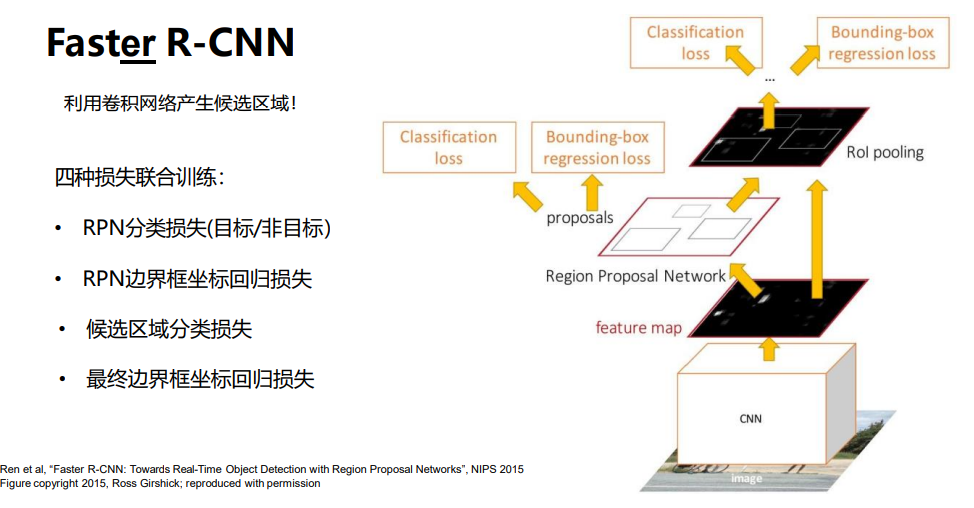
RPN分类损失只是判断该区域是不是目标;

整个训练过程:先对整个图像进行卷积,得到特征图,然后分别对每个像素点进行区域划分回归,选择就有可能是目标区域的300个区域进行区域裁剪,然后再进行分类和区域定位。

YOLO是速度比较快的,虽然可能精度上没有Faster R-CNN高,但是性价比是比较高的;

