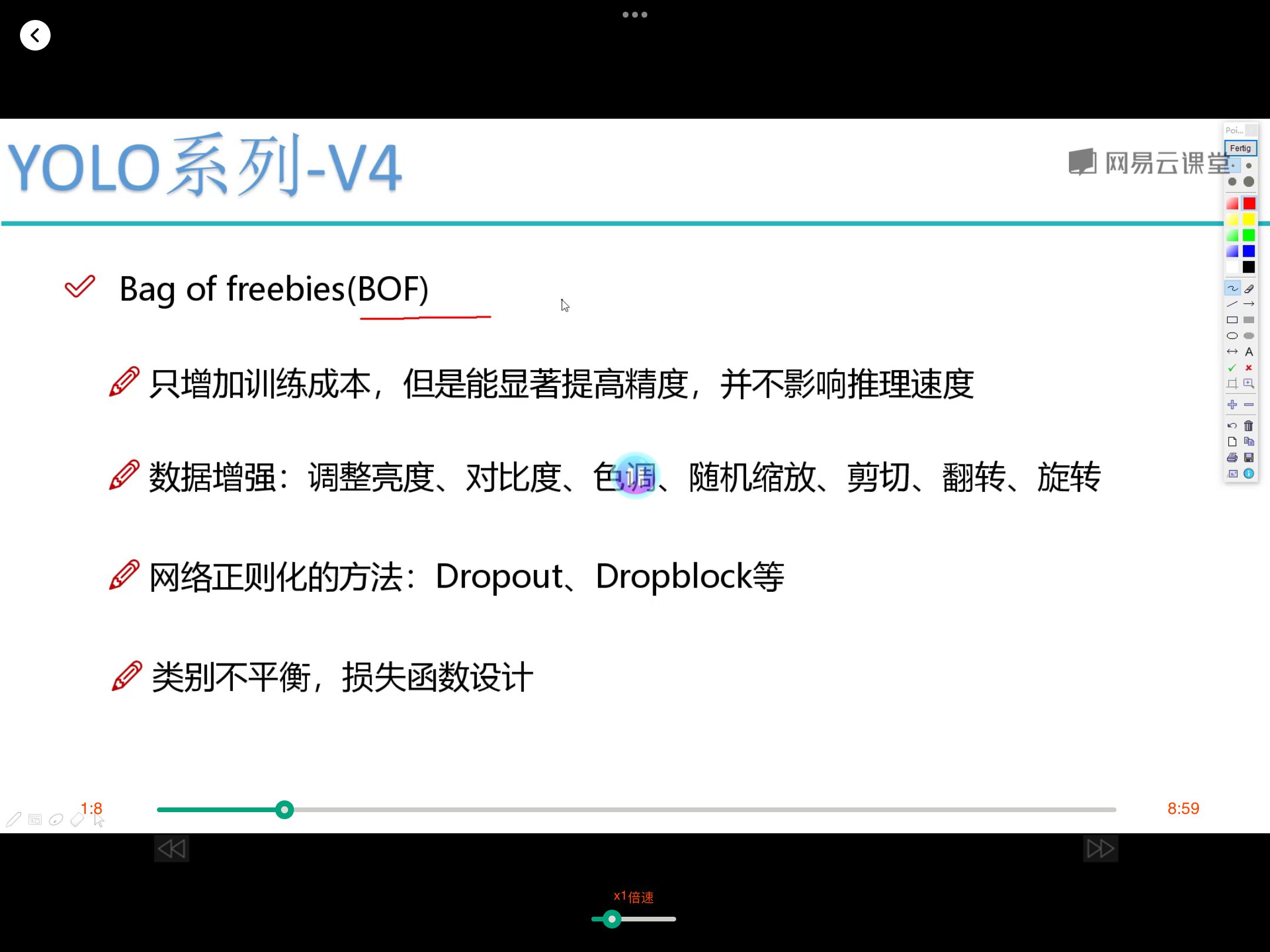
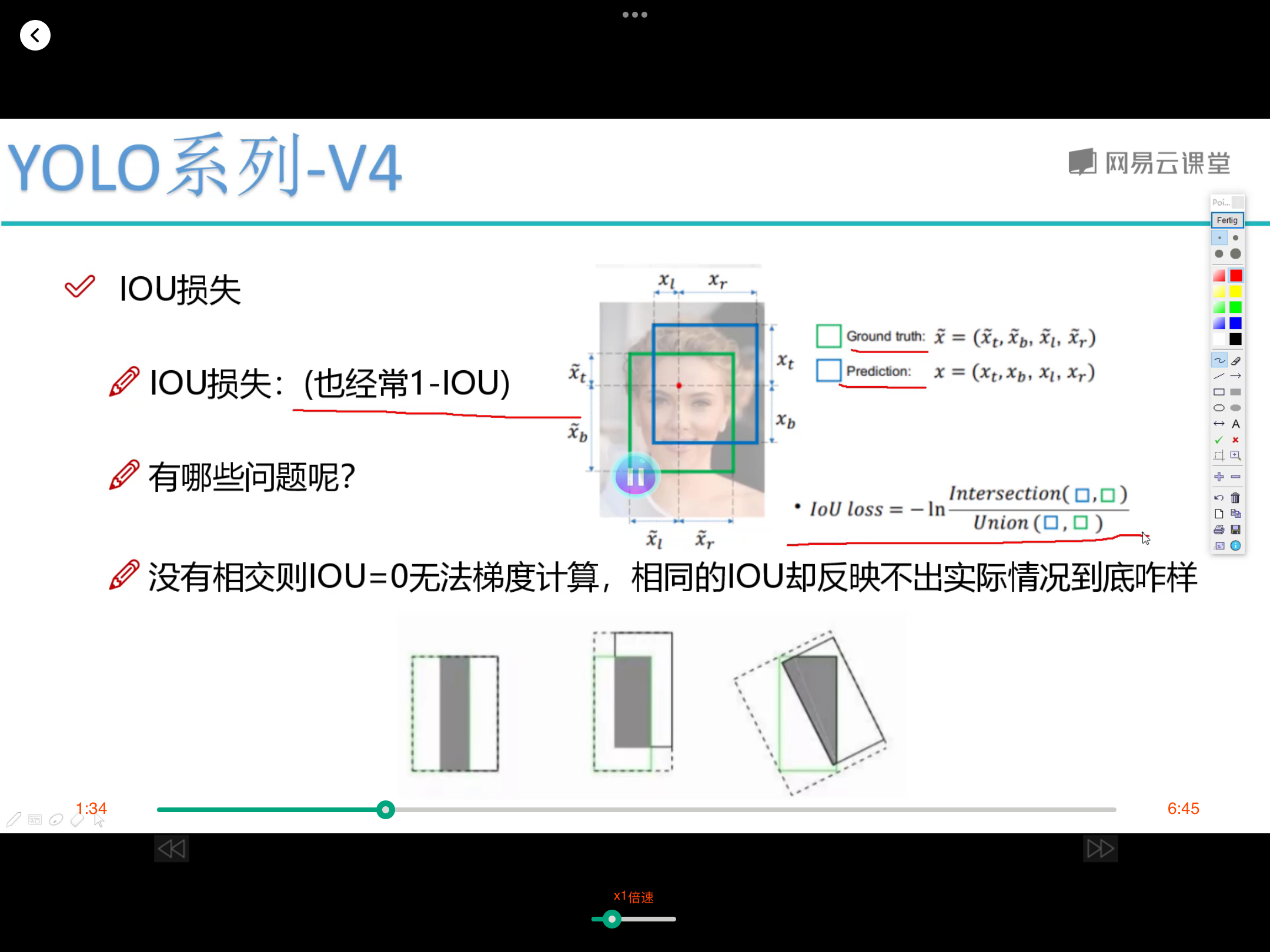
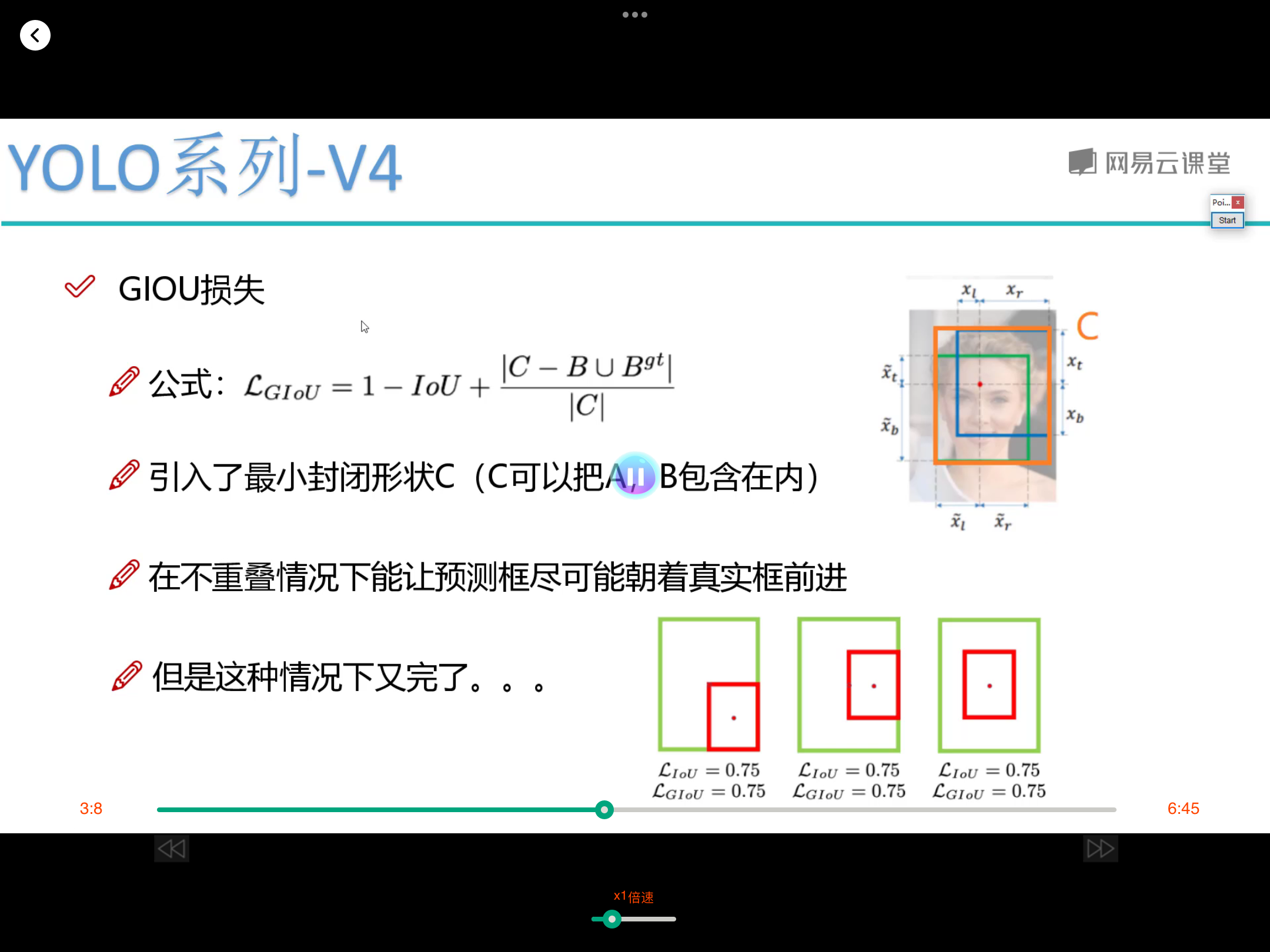
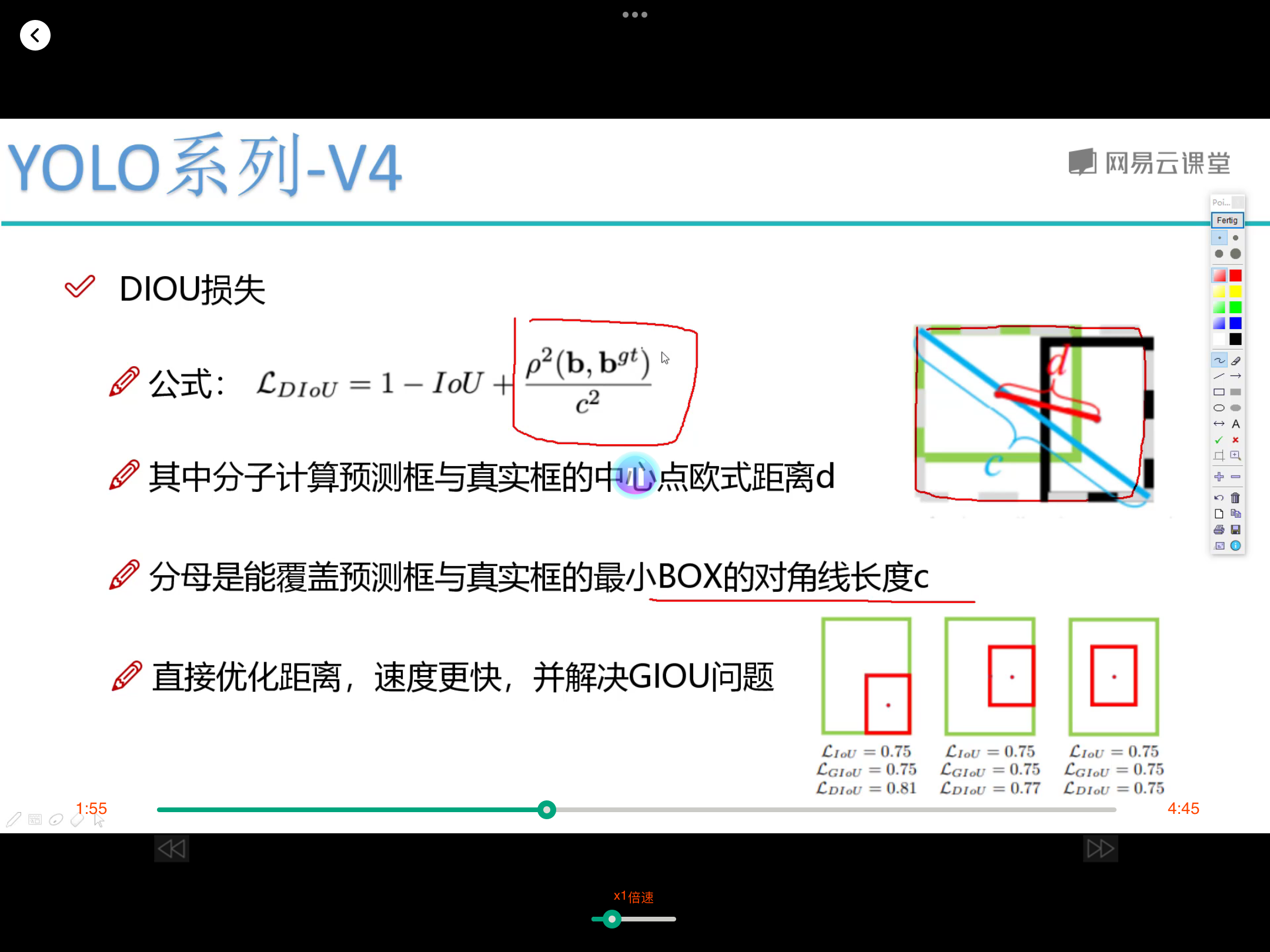
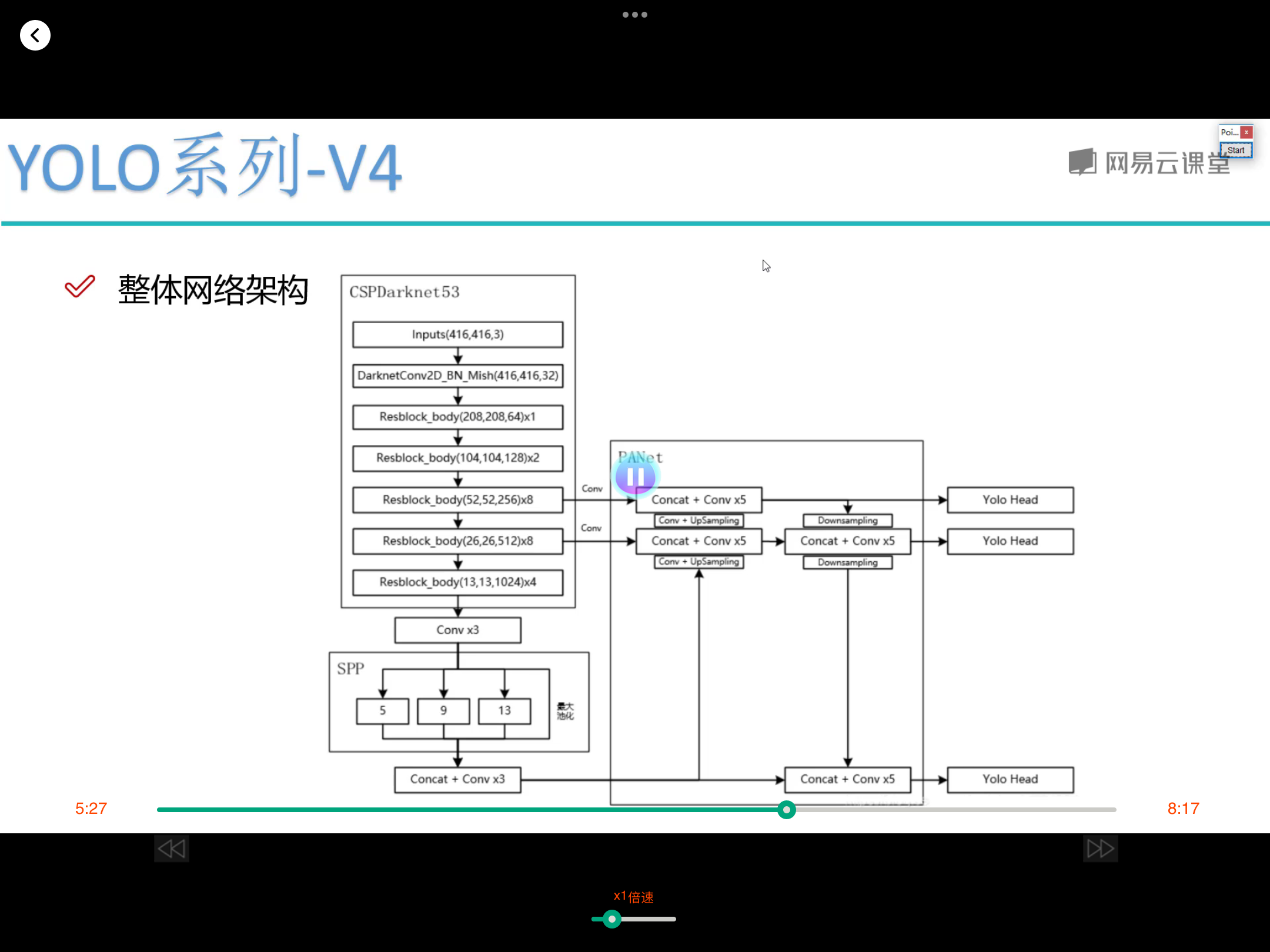
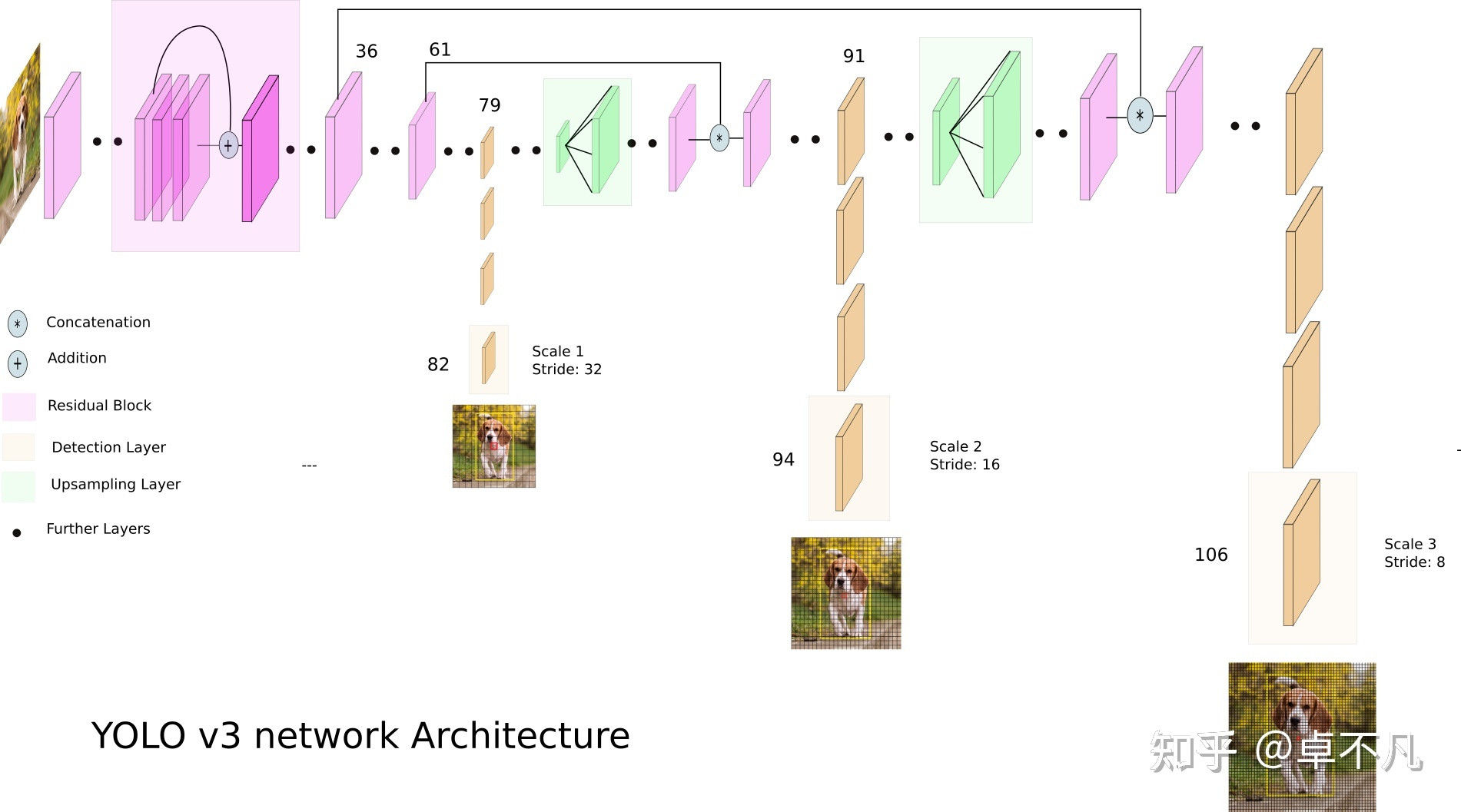
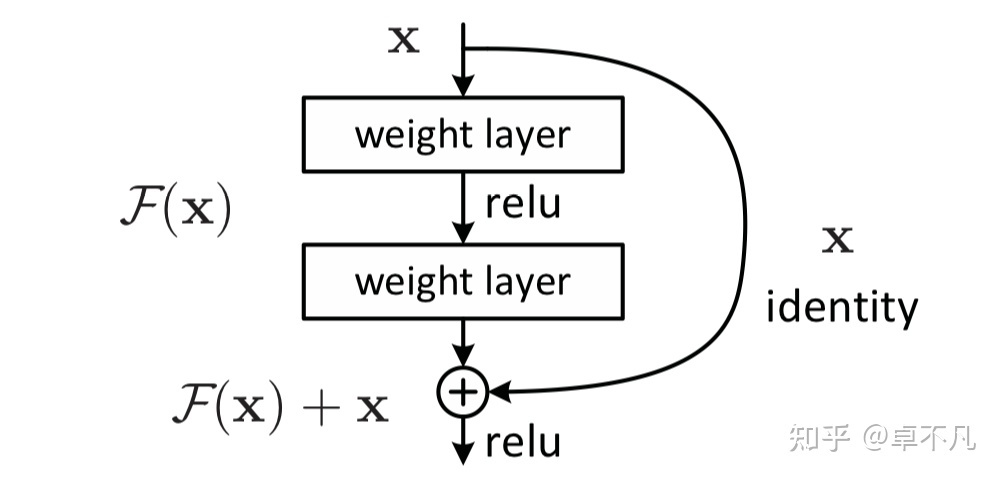
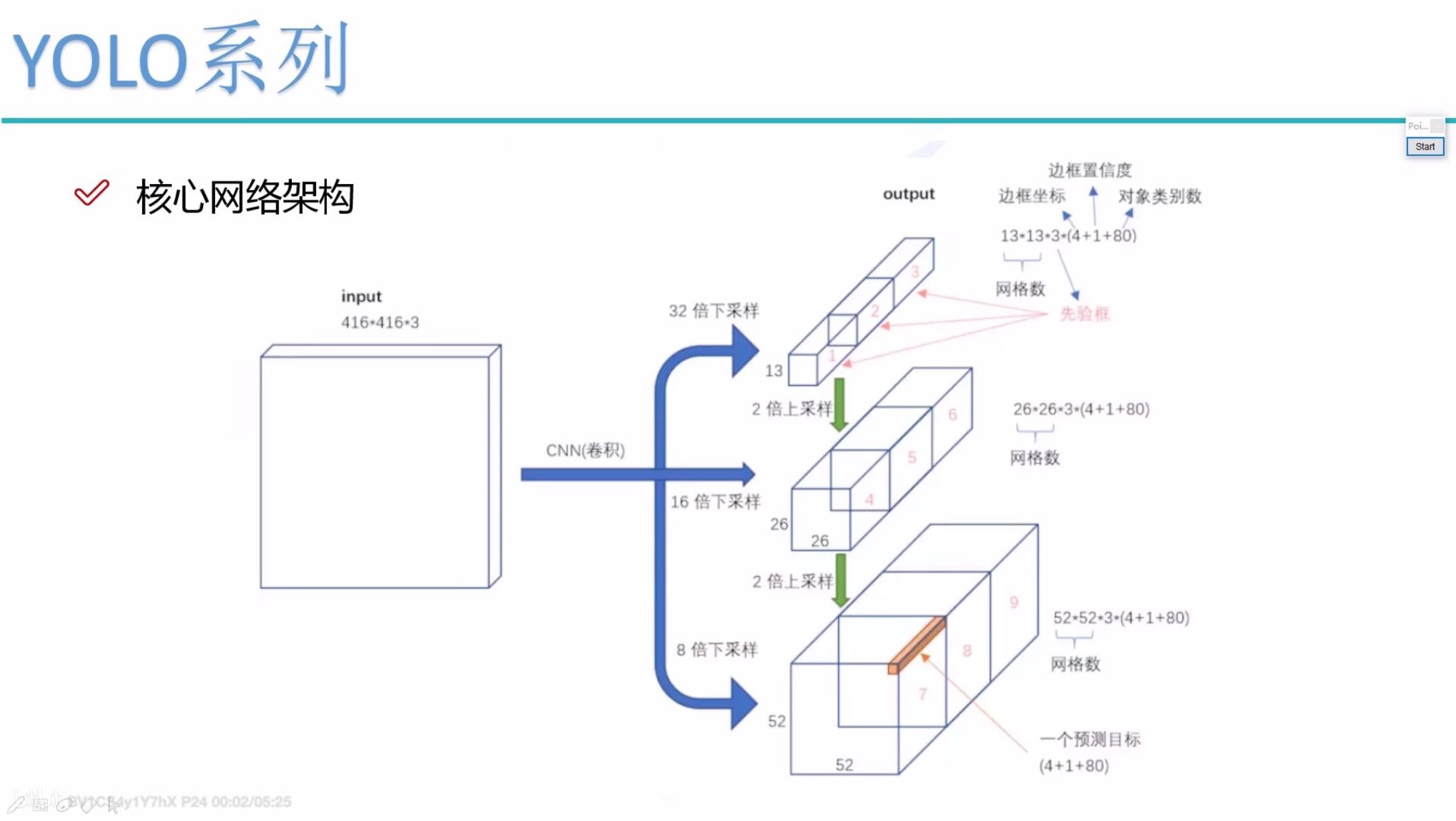
对dataframe数据集构建dataset
1 | # -*- coding: utf-8 -*- |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class TrainDataset:
def __init__(self, data_path, width_height, classes):
self.df = pd.read_pickle(data_path)
self.w_h = width_height
self.classes = classes
def __getitem__(self, item):
image = self.df.iloc[item, 0]
label = self.df.iloc[item, 1]
image = Image.fromarray(image).resize((self.w_h, self.w_h), resample=Image.NEAREST)
image = np.array(image)
image = torch.from_numpy(image)
label = torch.tensor(label)
image = F.one_hot(image.to(torch.int64), 3)
# label = F.one_hot(label.to(torch.int64), self.classes)
image = np.array(image).transpose((2, 0, 1)).astype(dtype=np.float32)
image = torch.FloatTensor(image).contiguous()
# label = label.contiguous()
return image, label
def __len__(self):
return len(self.df)